

12 minute read
Most businesses deal with countless text-based documents and messages daily, from customer queries and survey responses to product reviews and user mentions on social media.
These are all known as "unstructured" data.
Text mining is the most practical and fastest way to sort through all the text to transform, structure, and classify the textual data for easier analysis.

Text mining tools use artificial intelligence (AI) techniques, specifically natural language processing (NLP), to identify human language and process it automatically.
As a subset of data mining, this process discovers patterns in language, identifies trends, and uncovers valuable information hidden in text messages and documents.
These text mining tools analyse unstructured data and turn it into more accurate, consistent, and actionable information.
For example, they can help you understand customers' buying behaviour, discover key topics for marketing campaigns, and build better products based on what people want.
But, with so many text mining tools on the market, which one should you use?
Tool 1: Datavid Rover
Datavid Rover is an AI-powered engine you can use to make the most of your organisation's data.
It's a simple solution that can help both experienced users and novices without needing expert knowledge of coding or programming languages.

You can use it to extract, enrich, and discover the most valuable information from data across departments in your organisation.
It extracts data from documents securely and ensures compliance across multiple regulations.
Core features of Datavid Rover
The biggest selling point of Datavid Rover is its ability to research large amounts of text data from thousands of documents and use data intelligence to transform it into actionable knowledge.
Some features are:
- Data connectors support: Datavid Rover text miner provides connectors to various popular data services, including IBM Cloud, AWS S3 Buckets, and Microsoft SharePoint, among others.
- No-code information extraction: The text miner features a training system to extract entities and form relationships without the user writing a single line of code.
- Powerful search and analysis: Users can conduct research faster, they can extract intelligent insights from large amounts of data, and use powerful cognitive search to make data actionable. This significantly reduces the time it takes to find and analyse information.
- Data training with data filtering: Datavid Rover allows you to train it with ontologies and data filtering capabilities based on your needs while ensuring compliance.
It is a product that can mature further and implement its potential.
Datavid Rover makes it easy for your enterprise to analyse all data in one place.
It stands out from the rest for its simple interface and streamlined data ingestion, discovery, and classification.
Tool 2: SAS Text Miner
SAS Text Miner is a high-performance text mining tool built for businesses that want to easily collect and analyse data from the web.
It can find and analyse text data from various sources - from comment fields and blog mentions to books and documents.
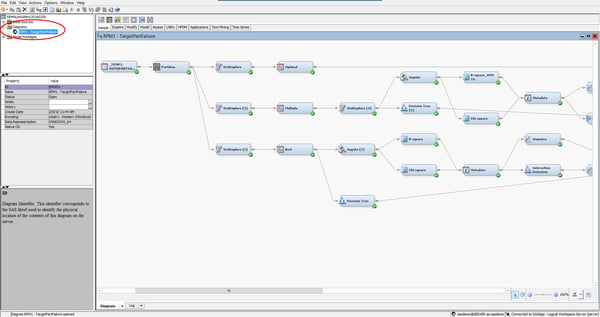
Source: SAS Communities Library
SAS Text Miner tool also learns from custom models and collects data to improve its performance and efficiency with time.
Core features of SAS Text Miner
High-performance text mining is the selling point of SAS Text Miner; it quickly evaluates large amounts of text from a variety of sources.
Some other features are:
- Automatic Boolean rule generation: The software can automatically create true or false rules streamlining text classification.
- Term trending and profiling: Efficiently evaluates how relevant specific terms in a collection are to figure out its usage trends and relevance.
- Visual analysis of results: SAS Text Miner analyses results visually to uncover how terms relate and output accurate results.
This is a good choice, but you have to keep in mind that it requires training to use, and the program can take time to study a large quantity of data.
SAS Text Miner supports multiple languages. Its intuitive interface allows you to drag and drop labels and integrate the miner with other SAS software tools.
Tool 3: DiscoverText
If you have a team that collaborates on a task and are looking for a text mining tool they can use to analyse text collaboratively, you should try DiscoverText.
This tool is ideal for a business that relies on Twitter for marketing or information discovery. While DiscoverText can be ideal for individual small businesses, larger companies will likely need a more developed solution.
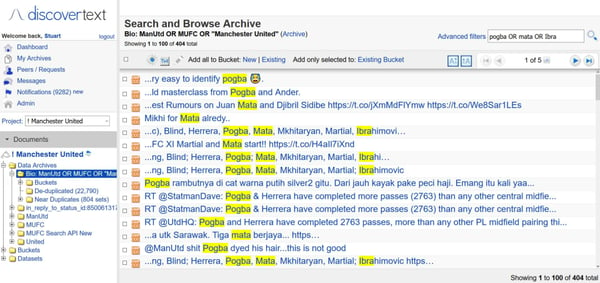
Source: Software Advice
With supporting videos created by the founder, DiscoverText is a multilingual text analytics tool that uses human annotation, data science, and machine learning features.
Core features of DiscoverText
DiscoverText is the best in terms of possibilities for collaborative work.
Some other features are:
- Advanced text search and sampling: Integrated eDiscovery tools that are highly efficient in deduplicating and automatically clustering near-duplicate data.
- Custom sifting: DiscoverText uses powerful text-sifting techniques to ensure that data is accurately classified and presented.
- Twitter integration: Uses high-level data landscape sensing to construct digital footprints of viral and relevant tweets.
- Human input: Users can continually input terms and data to improve the tool's learning process and the quality of its results.
- Redaction crowdsourcing support: DiscoverText features a crowdsourced document redaction capability of metadata and personal information for academics and legal teams.
One problem this tool has is that there are export restrictions and limitations.
DiscoverText's point-and-click graphical user interface makes this tool easy to learn and use.
Tool 4: IBM Watson
IBM Watson is a cost-saving suite of software, including a text mining tool, that can be used to discover insights in large amounts of text data.
Over the years, IBM has refined the Watson suite of AI tools to make it comprehensive and personalisable for any business or organisation.
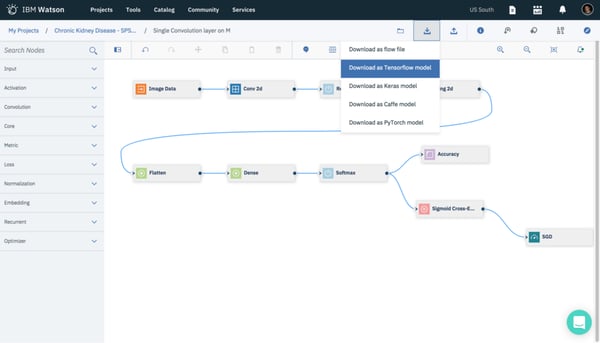
Source: Medium
IBM Watson's text mining capabilities include natural language understanding, sentiment analysis, and entity extraction.
It also provides real-time insights from data-driven content through visualisations and other cognitive services like machine translation and speech-to-text conversions.
Core features of IBM Watson
The best feature of IBM Watson is its availability in multiple languages.
Some other features are:
- Watson assistant chatbot: Businesses can integrate a chat box onto their website to provide live, automated customer service.
- Visual recognition capability: IBM Watson features tools to recognise objects, including text, in images and to process and classify them into relevant categories.
- Text discovery: Watson discovery is a feature that unlocks the value of data by discovering text and monitoring trends. It also manages surface patterns and uses NLP to build contexts and relationships in mined texts.
- User-friendly: The results come in an easy-to-digest format that makes it easy for users to interpret the findings.
- Smart Document Understanding: This is a visual ML tool that understands the critical components of enterprise documents.
IBM Watson supports deep learning, so it can learn from its mistakes and improve, but it takes time and effort to teach IBM Watson to use it to its full potential.
Users can mix and match the various tools with their core text miner to create an ideal AI solution that meets their needs.
Tool 5: Google Cloud NLP
Google Cloud NLP is a set of natural language tools pre-trained by Google and ready to integrate into other Google Cloud services or with the ones with an API.
Businesses of all sizes can easily use Google Cloud NLP to mine and analyse text from unstructured data.
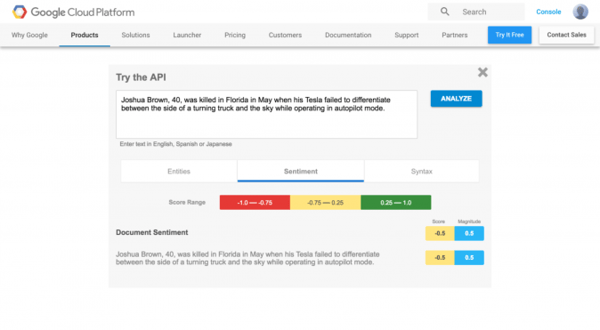
Source: Cloud Academy
This tool uses advanced deep learning algorithms to analyse text-based content and deliver relevant insights for your business objectives and has multi-language support.
It has robust features that allow you to extract meaning from text documents, images, and video clips. You can use it to analyse large amounts of content to find patterns, summarise the content and compare different sources of information.
Core features of Google Cloud NLP
Google Cloud NLP stands out for its high-performance syntax analysis: it analyses natural language with grammar rules (parsing).
Some other features are:
- Personalisation for sentiment analysis: Users can personalise this tool to get insights from large volumes of unstructured texts. This leads them to a better understanding of sentiments, conversations, and information about people, events, and places.
- Simplified entity extraction: As a natural language processor, Google Cloud NLP eliminates the need to conduct manual analysis to identify entities. It also integrates with other Google services to verify entities, such as Google Maps for addresses.
- Building custom relationships between content: Businesses can use Google Cloud NLP to find and organise large amounts of text using custom brand-specific entities.
- Easy REST API access: Businesses can use an API to mine data from cloud storage and other locations without the need to pre-train datasets.
Users must train custom models to mine, classify text, and uncover entities within documents. Luckily, this process is well-documented and easy to understand.
Google has made it easier for businesses to build custom models based on existing templates to meet their specific needs.
Tool 6: MeaningCloud
MeaningCloud is a software for text mining and analytics used by organisations looking to implement text mining in their operations.
It is popular among businesses in the banking, insurance, and publishing industries and for consumer-facing industries that need to stay on top of social media conversations.
It's simple, fast, and effective.
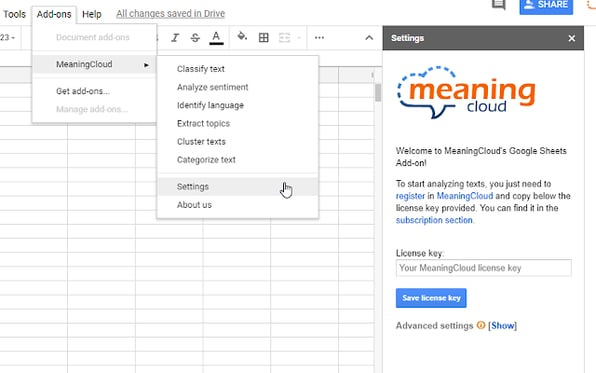
Source: MeaningCloud
MeaningCloud is typically used to extract and analyse data from surveys, contracts, news posts, call transcripts, and customer service chats.
It's a cloud-based tool that works in your browser, so you don't need to download anything onto your computer.
Organisations also use MeaningCloud to mine text on social media platforms and forums to understand and summarise conversations in different languages.
Core features of MeaningCloud
This tool is highly customisable: Users can personalise the functionalities for analysing data using their own models and dictionaries.
Some other features are:
- Multiple language support: MeaningCloud can analyse content in over 50 different languages.
- Powerful sentiment analysis: MeaningCloud's outputs generate custom reports, conduct sentiment analysis, and streamline content for publishing. It can also analyse customers' feedback (emails, sales calls, etc.).
- Easy third-party services integration: Add-ins and plug-ins make it easy to integrate MeaningCloud with various document processing tools and web services.
- Social media monitoring: Organisations can integrate this text mining tool into their social media platforms to discover and process large amounts of posts and to discover trends.
MeaningCloud is not available as a stand-alone platform, but only as an add-on to Excel or as a cloud API.
The developers of MeaningCloud promote it as a document and people analytics tool that can be the customer's voice. It offers a cost-efficient way to analyse unstructured data in a single, centralised location.
Tool 7: Textable
Free and open-source text mining tool Textable is an AI text mining solution for firms looking to analyze text.
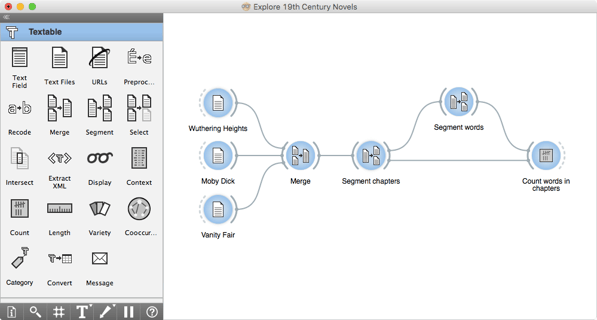
Source: Textable
With this text mining tool, teams can build machine learning models that they can use to process and analyse visual text faster.
Core features of Textable
Textable main feature is its free basic text analysis: It can analyse, filter, and extract letters, words, sentences, and full-query texts using regular expressions.
Some other features are:
- Advanced text analysis: Textable can also process collocations and concordances based on annotations, process segment distributions, and use many advanced data mining algorithms.
- File import and export: Use Textable to import and export text data from and to various sources. It supports most text encodings, including Unicode.
- User-friendly interface: An intuitive interface makes Textable easy to learn. There is also a huge community and ready-made recipes for advanced users.
It is flexible and free to use but may take new users some time to learn to use its text-mining recipes.
Textable is a visual text mining tool with simple analytic workflows and simple graphical tools.
Tool 8: Amazon Comprehend
Amazon Comprehend is a powerful text-mining tool that can help you extract meaning from your data.
It is a good tool for both beginners and advanced users.
It's simple to use and powerful enough to analyse large datasets.
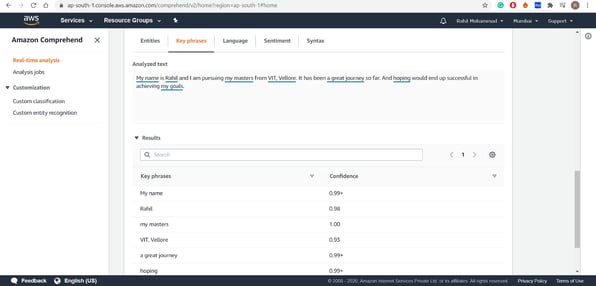
Source: Amazon Comprehend
It's a natural language processing (NLP) API that makes it easy to understand the content in any document or text.
Core features of Amazon Comprehend
Sentiment and syntax analysis are the most relevant aspects of this tool. It automatically generates a summary report that explains how many times each entity appears in your text and its sentiment score (positive or negative).
Some other features are:
- Keyword extraction and research: It is possible to find relevant keywords on your documents, including PDFs, images, and web pages, and find mentions of specific keywords, which can be helpful for keyword research and content optimisation.
- Review and social posts: This tool's NLP capabilities allow you to extract key insights from unstructured data such as customer reviews and social media posts. It can also identify entities such as people, places, and organisations.
One negative aspect of Amazon Comprehend is that it is quite new. As such, the interface misses some features of older programmes.
With Amazon Comprehend businesses can build a custom set of entities or text classification models tailored to their organisation’s needs.
Tool 9: Aylien
Aylien is a simple-to-use text-mining tool focused on the world of news. It aggregates news and helps you monitor media mentions.
It is an excellent option for beginners who need a simple way to uncover insights from extensive text data. It is also good for businesses with developers and data scientists who need to extract information from large data sets quickly.
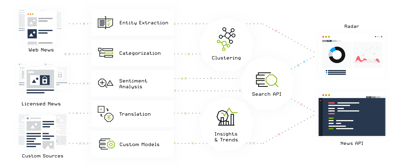
Source: Aylien
Core features of Aylien
Aylien's selling point is its news aggregation capabilities and context recognition. This tool can understand the context of your text and automatically identify entities.
Some other features are:
- Entity extractions and classification: The tool enables the creation of highly accurate topic models and the discovery of relationships between data sources.
- Topic modelling: The tool enables the creation of highly accurate topic models and the discovery of relationships between data sources.
- API: It provides sentiment analysis, entity recognition, and other features related to unstructured data analysis.
Aylien is highly specialised in news, so it may not be the best solution for analysing other types of content, such as reviews or longer documents.
With Aylien you can input a large amount of unstructured data and then view it in an easy-to-read format by highlighting all relevant information.
Tool 10: Apache OpenNLP
Apache OpenNLP is popular Java software that can be installed on Windows, Linux, macOS X, and other platforms.
It is ideal for businesses and organisations dealing with long texts and documentation.
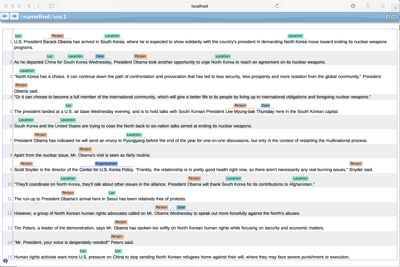
Source: Apache OpenNLP
Apache OpenNLP is an open-source tool you can use to perform NLP tasks.
Core features of Apache OpenNLP
It is the best for document categorisation.
Some other features are:
- Language detection: It recognises the language in which a text is written.
- Parsing and tokenisation: It can parse text into tokens and phrases and classify those tokens based on their part-of-speech tags.
- Named entity recognition (NER) and extraction: It can recognise named entities (people, places, things) and extract information from them.
- Semantic role labelling (SRL), sentence boundary detection, and part-of-speech tagging: Apache OpenNLP uses a set of annotators to extract information from text documents. Each annotator can identify a specific type of linguistic entity in a document, such as person names or dates, or perform a particular type of transformation, such as sentence boundary detection or part-of-speech tagging. These annotators are in a pipeline configuration, which allows them to be chained together in any order.
- Setting parameters: You can configure each annotator with the specific parameters it needs to perform its task. These parameters can include the type of information you need from the text, the resources you should use for processing, and how strict you want the annotator to be in its analysis.
This tool sometimes lacks fast update releases, and its chunking and parsing can be improved.
This tool is highly flexible and allows you to create custom configurations for each type of annotation needed for your project.
Recap table: Pros & cons of each tool
The best tools for analysing unstructured data are easy to use and allow quick results, but there are more factors to consider when selecting the right tool for your business.
Here you have a sum up-comparison to help you decide:
| TOOL |
SELLING POINT |
PROS |
CONS |
|
DATAVID ROVER |
A complete “knowledge engine,” it is the best solution for researching large amounts of text data from thousands of documents and using data intelligence solutions to transform it into actionable intelligence. |
- Data connectors support - No-code information extraction - Powerful search and analysis - Data training with data filtering - Simple interface - Streamlined data ingestion, discovery, and classification |
It is a product that can mature further and implement its potential |
|
SAS TEXT MINER |
It is the best solution for high-performance text mining and quick evaluation of large amounts of text from various sources. |
- Automatic Boolean rule generation - Term trending and profiling - Visual analysis of results |
- It requires training for the use - The program can take time to study a large quantity of data |
|
DISCOVERTEXT |
It is the best solution in terms of possibilities for collaborative work. |
- Advanced text search and sampling - Custom sifting - Twitter integration - Human input - Redaction crowdsourcing support |
Export restrictions and limitations |
|
IBM WATSON |
It is the best solution for multiple languages. |
- Chatbot - Visual recognition capability - Text discovery - User-friendly - Smart Document - Understanding |
It takes time and effort to teach IBM Watson to use it to its full potential |
|
GOOGLE CLOUD NLP |
It is the best solution for high-performance syntax analysis |
- Personalization for sentiment analysis - Simplified entity extraction - Building custom relationships between content - Easy REST API access |
Need to train custom models to mine, classify text, and uncover entities within documents |
|
MEANINGCLOUD |
It is the best solution for the customisation of functionalities. |
- Multiple language support - Powerful sentiment analysis - Easy third-party services integration - Social media monitoring |
Not available as a stand-alone platform, but only as an add-on to Excel or as a cloud API |
|
TEXTABLE |
It is the best solution for free basic text analysis. |
- Advanced text analysis - File import and export - User-friendly interface - Flexibility |
It takes time for new users some time to learn to use its text-mining recipes |
|
AMAZON COMPREHEND |
It is the best solution for sentiment and syntax analysis |
- Keyword extraction and research - Review and social posts |
The interface misses some features |
|
AYLIEN |
It is the best solution for news aggregation and context recognition |
- Entity extractions and classification - Topic modeling - API - Sentiment analysis - Entity recognition |
Not be the best solution for non-news content |
|
APACHE OPENNLP |
It is the best solution for document categorisation. |
- Language detection - Parsing and tokenisation - Named entity recognition (NER) and extraction - Semantic role labelling (SRL), sentence boundary detection and part-of-speech tagging - Setting parameters |
- Lack of fast update releases - Chunking and parsing can be improved |
Selecting a text mining tool for your business
Text mining is a powerful process for uncovering valuable insights from unstructured data.
It can help you transform any significant volume of text into structured knowledge. These 10 tools are a great place to start if you're looking for a way to parse the text in your data.
They offer a variety of features and functionalities that can help you analyse text in different ways. But there are always trade-offs when you use technology—so it's vital to think about what will work best for your business.
If you want to get started, consider Datavid Rover as a starting point.
It has many features you need to get started with text mining, including a user-friendly interface and a robust set of features perfect for entity extraction, sentiment analysis, and more.



