

9 minute read
Text mining and data mining are two similar terms, but you can't use them interchangeably. Data mining is for relational data, text mining unstructured data.

While the two have the same purpose—to find valuable insights from the data—their approach and application differ.
Text mining is extracting meaning from unstructured text data using various techniques such as statistical modeling, natural language processing (NLP), etc.
Data mining analyses large amounts of data to identify patterns, trends, and other helpful information by applying machine learning algorithms, statistical analysis techniques, and database management methods across multiple sources, including structured and unstructured data.
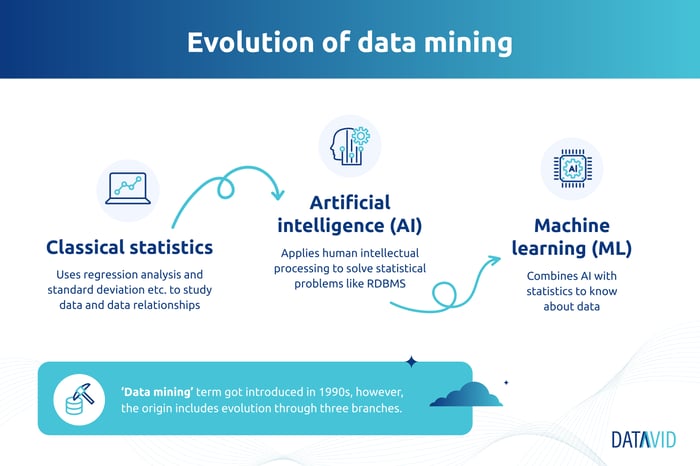
Data mining: A quick explanation
Data mining is extracting helpful information from a large set of structured data. It's a big field that uses statistical techniques to analyse data and uncover hidden patterns, trends, and associations.
It's often used in science and business to discover new knowledge, for example, by finding hidden correlations in data.
The goal is to discover meaningful patterns in a large amount of data that can be useful in making predictions or decisions. You can use data mining to analyse many different types of data: text, images, video, audio, etc.
The value of data mining
Data mining can help in many industries, including retail, healthcare, finance, education, and more. The value of data mining has increased as the amount of available digital content has grown exponentially over the past few decades.
Companies can use these patterns, trends, and associations to make strategic business decisions. Researchers can also use it to discover new trends and patterns in data and by government agencies to predict future events.
It's also one of the most effective ways to make sense of data.
It allows companies and researchers to find patterns, trends, and associations in large amounts of information that would otherwise be impossible or time-consuming to discover manually.
Text mining: A subset of data mining
Text mining is a subset of data mining because it focuses on analysing unstructured text. Unstructured data, also known as "free text," is any type that doesn't fit into a predefined format and can't be easily categorised.
This includes blog posts, emails, news articles, tweets—anything written by humans that isn't already part of some other system.
(Like an Excel spreadsheet or database)
The problem with unstructured data is that it's challenging to analyse.
It doesn't come in a format that computers can efficiently process, so humans need to manually go through each piece of information and select certain parts for analysis. This process can take days or weeks, depending on how much data you're dealing with and how many people you have available to help.
Text mining has emerged as a valuable tool in its own right due to the information it can yield from unstructured datasets, but it's not a panacea.
The more advanced your text mining becomes, the more specialised skills you need to do it effectively. This can make it prohibitively expensive for many businesses—especially those that don't have a large budget for IT support.
Still, text mining can be a powerful tool for enhancing your business intelligence and better using your existing data. By combining it with other types of information analysis, you can extract more value from your data than ever before.
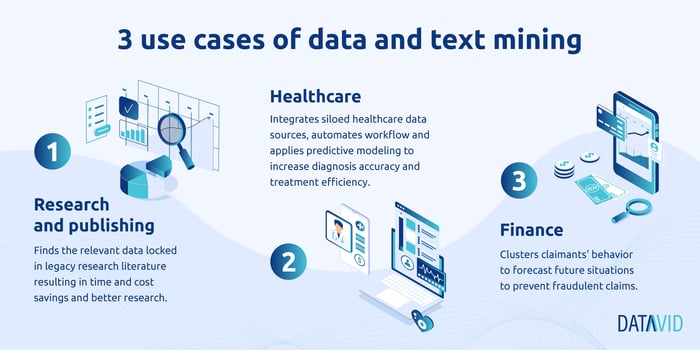
The value of text mining
Text mining has the potential to provide companies with a wealth of information about their customers, including behavioural patterns and sentiment (the kind of data you cannot extract using data mining or statistical analysis alone).
With text mining, you can use natural language processing (NLP) to analyse large amounts of data and better understand how customers feel about your products or services.
You can use this to improve customer service, increase sales conversions, and reduce churn. But text mining extends beyond just learning more about your customers—you can use the data to improve your internal processes as well.
For example, using the results of a customer survey, you might notice that many customers are unhappy with their experiences at one particular store in your chain of locations.
This could be an opportunity to make improvements across all stores and increase overall customer satisfaction levels. It can also help better understand customers' needs and preferences, which can help companies design new products.
Data mining vs. text mining: The full comparison
Data mining and text mining are two different concepts that often need clarification from one another. So here's a complete comparison:
High-level overview
The most significant difference between data mining and text mining is the type of data they analyse.
Data mining uses structured data, which you can organise in a database or table. Instead, text mining focuses on unstructured data, such as documents and emails.
In data mining, you're looking for patterns in data that can provide valuable insights into your customers.
This is often done with the help of rule-based algorithms that allow computers to find trends and associations within large amounts of data and then apply them to make better business decisions. You can do this using several methods, including predictive analytics and machine learning.
Text mining tools allow you to analyse documents (such as emails) to understand how people feel about specific topics or products.
This analysis helps identify trends or patterns within large amounts of text data so that companies can make more informed decisions about their customers' needs.
Analysing the free text is harder because it requires a combination of techniques such as machine learning model training and concept classification.
Data types and categorisation
In text mining, the dataset is text (anything from a few words to an entire book or article). Data mining data is numerical data (like sales data or social media usage).
Text mining uses different algorithms compared to data mining.
For example, data mining algorithms often use statistical methods like regression or logistic regression based on numbers and can be applied across large datasets.
Text mining algorithms rely on machine learning and natural language processing (NLP) techniques such as clustering and classification.
To succeed at text mining, you need to have a lot of data available to train your algorithm with enough examples of what you're looking for.
Data miners usually use statistics-based methods because their design depends on large amounts of known data. Meanwhile, text miners don't have much luck using these techniques because they require a particular set of parameters that only sometimes exist with text analysis methods.
Ontologies and taxonomies
An ontology is a formal representation of knowledge that allows computers to understand what people mean when they use certain words.
This will enable companies to create taxonomies for their products, services, and customers. With an ontology in place, you can use machine learning algorithms to analyse and classify data more quickly and accurately than ever.
Taxonomies are organised lists of terms that describe a topic.
They help organise information in a way that's easy to understand and search through. Companies use taxonomies to make sense of their data by creating relationships between words, concepts, objects, and people.
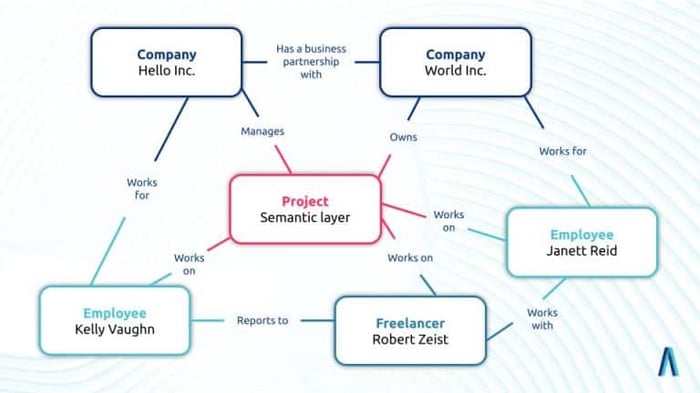
Data mining and text mining use ontologies and taxonomies as a reference to identify the most important concepts, people, or things in your data.
They also help you classify information to find patterns and trends.
Taxonomies are also helpful in organising large amounts of unstructured data.
For example, when working with an extensive collection of journals, books, or scientific papers, you can use taxonomies to create relationships between them and make better sense of the information.
The most common use of ontologies and taxonomies is to build a knowledge base, an organised collection of concepts, and relationships between them.
You can then use this knowledge base to help you analyse unstructured data.
For example, your knowledge base will allow you to identify the essential terms in discussions to understand how people talk about a particular topic. You can then use this information to identify your business's most relevant and vital topics.
Using ontologies and taxonomies is vital to text mining because it helps you identify which concepts are essential in the data.
Without a taxonomy or ontology, you would have to manually code your unstructured data and then manually map those codes back to concepts—a recipe for a lot of human error and wasted time.
By having an ontology or taxonomy, you can automatically tag your unstructured data with concepts, which makes mapping it back to the right topics much more manageable.
Processing and retrieval
When comparing the two approaches, text mining is often more accurate and efficient than data mining.
This is because you can use it to process large amounts of unstructured data, allowing users to get results much faster than traditional methods.
On the other hand, data mining relies on structured data.
This means that if your data isn't in a format that you can quickly analyse by computers (such as spreadsheets), it won't work well for this purpose.
However, text mining software has several limitations.
For example, you can't use it to discover relationships between events or data points; if you want to find out how time-sensitive information is connected somehow, you'll need to use more structured approaches instead.
Discovery and analysis
You can use data mining and text mining software together to perform various tasks. For example, you may want to use data mining to discover patterns in your data; then use text mining to classify the remaining unstructured concepts.
This combination lets you get more out of your data than just one method alone.
This means you can use it to uncover relationships between different types of information in your database, including numbers and dates.
Text mining vs data mining: Recap table
Use the table below as a high-level reference guide. For more information on each category of comparison, refer to the individual sections above.
| CATEGORY | DATA MINING | TEXT MINING |
| Overview | Uses statistical methods to search for patterns mainly in structured data, such as relational databases. | The subset of data mining which involves processing of unstructured textual data into structured information to enable data analysis. |
| Purpose | Used to mine information from multiple data sources and bring them together into one view. | Used to extract concepts and real-world meaning from large amounts of unstructured text, enabling data analytics and insights. |
| Data sources | Structured data from large datasets found in systems such as databases, ERP, CRM, and accounting applications. | Unstructured text data is found in emails, documents, presentations, videos, file shares, social media, and the internet. |
| Data retrieval | Structured data is homogenous, organised, and easy to retrieve. | Unstructured text is heterogeneous, coming in many different formats and content types located in a more diverse range of applications and systems; it is not easy to retrieve. |
| Data preparation | Structured data is formal and formatted beforehand, facilitating the process of ingesting data to prepare it for analytical models. | It uses linguistic and statistical techniques to turn unstructured text into usable structured data, then applies analytical models. |
| Data processing | Processing of data is done via rule-based algorithms. | Processing of data is done through natural language processing. |
| Ontologies & taxonomies | There is no need to create or use ontologies and taxonomies. | As unstructured text comes in many different forms and formats, there is the need to have an overriding ontology for the data so that it can be organised into a common framework. |
| Techniques & skills required | Statistical techniques, probability, data cleansing, and artificial intelligence are used to process data. | Computational linguistic principles, pattern recognition, and natural language processing are used to process data. |
| Data types | Supports mining of mixed data, as long as the type is well-defined in a structured repository. | Mostly supports the mining of text present in file storage repositories. |
| Applications | Financial analysis, intrusion detection, spatial data mining, soft computing. | Risk management, fraud detection, customer care, semantic search, and knowledge management. |
Combining data and text mining
Data and text mining help you in extracting useful information from data. The difference is that text mining uses natural language processing (NLP) and machine learning techniques, while data mining uses traditional statistics methods.
You can use either one or both of these techniques in a variety of ways, such as:
- Getting insight into your business. Text analytics software can help you analyse customer sentiment about your products, services, or brand; identify new markets for expansion; or monitor social media trends among your target demographic groups.
- Better serving customers' needs and preferences before they buy something from you so that it's ready to ship by the time they pay for it online or in-store (known as "predictive analytics"). This might mean having enough inventory or providing recommendations in a timely manner.
- Understanding what your customers want, when they want it, and how much they're willing to pay for it (known as "prescriptive analytics"). This might mean stocking items in high demand at all times so that you can stay in stock during peak seasons or drops in sales.
- Understanding why people make confident purchase decisions, such as buying from one store or choosing one product over another (known as "exploratory analytics"). This can help you better understand your customers and how they make decisions, which will help you develop strategies for attracting new ones.
- Making more informed business decisions based on data you collect from all aspects of the supply chain (known as "decision support analytics"). This might include developing a pricing strategy or identifying which products are likely to sell well at certain times, as well as what to invest in.
- Analysing relationships between different variables to discover patterns in your data (known as "descriptive analytics"). This can help you identify trends, track seasonal sales, and understand the impact of changes on your business.
In general, text mining vs data mining is a question that often comes up. The best way to understand the difference between them is to look at their purpose.
Data mining helps analyse large sets of data and find patterns.
Organisations use it to find insights into trends or customer behaviour.
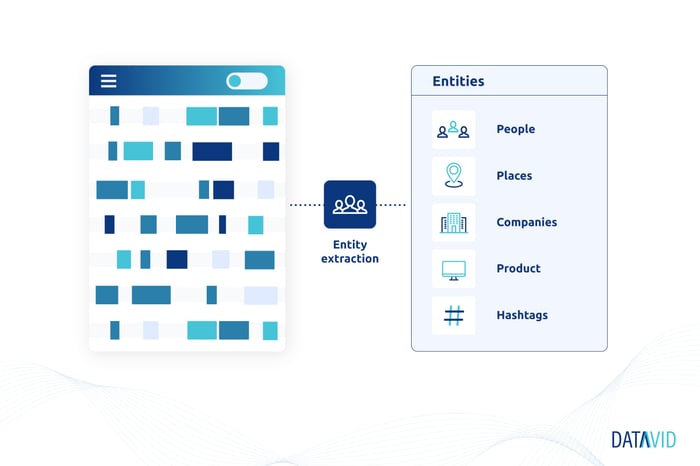
Text mining is used more for extracting information from unstructured text.
It can be helpful for sentiment analysis, which involves determining whether a piece of writing has a positive or negative tone.
If you want to find ways to improve your business, it's essential to understand the differences between these two technologies and how to use them effectively.
With help from Datavid's intelligence solutions, you can gain a more in-depth understanding of your customers, trends, and other factors that affect your business. By analysing the data you collect, you'll be able to make more informed decisions about improving your organisation's processes.



