7 minute read
Named entity recognition (NER) is important in delivering business value with natural language processing (NLP) techniques.
It allows you to train a program to recognise specific patterns and process information based on pre-set categories. The volume of tagging effort depends on the complexity of the task.

Let's look closer at why named entity recognition tagging matters and how to use it for your purposes.
What is named entity recognition (NER)?
Named entity recognition (NER) is the process of identifying, labelling, and categorising information in the text.
NER is a form of natural language processing (NLP) that allows machines to analyse and process natural languages.
NER identifies information from unstructured text and presents it to the user in a simplified format. This can have many applications across medicine, marketing, journalism, and HR.
How does NER work?
The main goal of NER is to identify and extract specific information from unstructured text. Common examples of classification categories are:
- Locations
- Names
- Organizations
- Date and time
- Email addresses
- Percentages
The program searches for the pre-defined entities in the text and classifies them as part of a certain category.
For example:
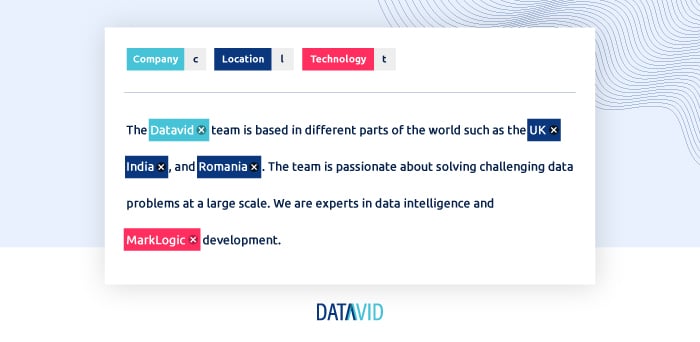
After analysing this text, the program identified the following elements:
Entities recognised with NER are proper nouns. They usually refer to places or organisations. However, they can also refer to specific things.
An entity can be one word or a series of words that always refer to the same thing. When implementing NER, you can create your own entity categories and set specific rules for which entities belong in each category.
NER challenges
While it seems straightforward, NER can be complex since the same entity may appear differently, for example, "UK" and "United Kingdom." This presents many challenges.
Four major NER challenges are:
- Ambiguity of words that have different meanings (e.g., "Rose" can be both a flower or a woman's name)
- Abbreviations (e.g., "New York City" can appear as "NYC")
- Spelling variations (e.g., "Megan" and "Meghan")
- Foreign words/names (e.g., "Londra" means "London" in Italian)
This technique is constantly developing, and the tools are improving at overcoming these challenges.
For example, ways to overcome the challenge of ambiguity in NLP are:
- Word Sense Disambiguation (WSD) uses context to identify word meanings. Specifically, it uses a given word and tests all possible meanings of the word in context. Nearby words and other context features aid classification.
- HMM (Hidden Markov Model) Tagger and Part of Speech Tagger are taggers that use probabilistic methods to resolve ambiguity using large corpora (e.g., Brown Corpus, WordNet, SentiWordNet).
- Hybrid combination of taggers with machine learning techniques
The business value of NER
NER makes the content easier to understand for different purposes.
It can help you quickly extract the necessary information from a large text, understand its structure, and identify relationships between entities.
Some common uses of NER in business include identifying client names in customer service transcripts, figuring out a user's sentiment towards your brand from their social media posts, identifying potential candidates from many resumes, and much more.
The greatest value of NER lies in saving time (and therefore money).
If your business requires you to make sense of a large body of text, NER is an excellent tool that you can use without spending hours reading it.
How NER tagging works
To determine an entity's identity, the NER tool must identify a word or a series of words (e.g., the United Kingdom) that form an entity.
Then, it has to analyse what category the entity belongs to.
For this to work, you must create relevant categories, such as Name, Country, Company, and the like and provide them to the NER tool. Next, by tagging specific words and phrases, you have to "show" the program which categories they belong to.
By processing your tags, the NER tool eventually learns how to recognise and categorise entities without your assistance. Some providers offer pre-trained NER models. If your goals aren't complex, you may not need to train a NER model.
NER tagging preparatory steps
NLP studies the structure of the language and creates a system that extracts meaning from the text.
As you can see in the image above, the key NER tagging steps include:
- Tokenisation
It is a technique of splitting the text into smaller tokens or parts (sentences, phrases, or words), so that each word can be analysed individually.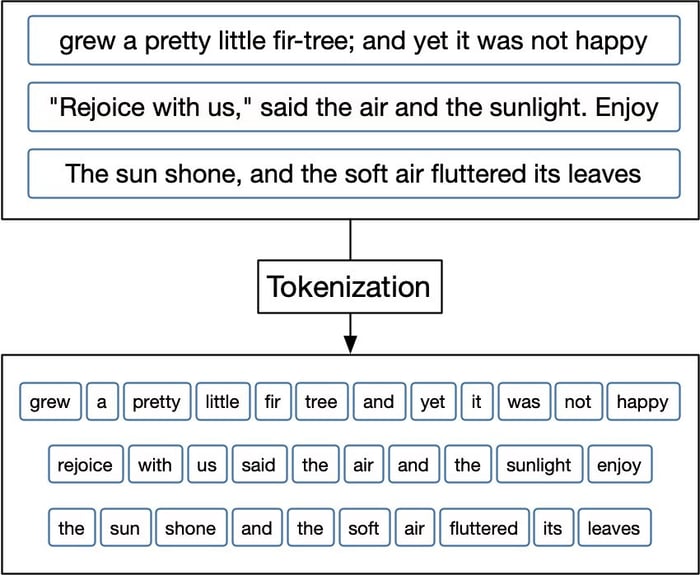
Source: Smltar
- Removing stop words
Such words as "the", "of", or "on" usually don't carry value for NER tagging, so they can be removed. However, there are exceptions depending on the content type. - POS tagging
It is a way to assign parts of speech tags to words. This and subsequent phases rely on machine learning to make generalised predictions about which tag is the most appropriate, whereas previous tasks can be programmed with formal rules.
This topic will also be discussed in more detail later. - Stemming or Lemmatisation
This consists in identifying the lemma (or root) of the word. For example, the words "jumped", "jumping", and "jumps" look like a variation of the same word to a human but appear as three absolutely different words to a machine.
Reducing them all to "jump" can minimise ambiguity and help with NER.
There are two main approaches to determining the lemma of a word with NLP:
-
- Stemming is a faster but more error-prone technique. It cuts off the end of a word in the hope of reaching the target.
- Lemmatisation is a technique that uses vocabulary and performs a morphological analysis to more accurately identify the lemma.
- Dependency parsing
It identifies relationships between words. For example, the machine should understand that in "white flowers", the word "white" is an adjective for the word "flowers". A special dependency tag would tell it about this relationship.
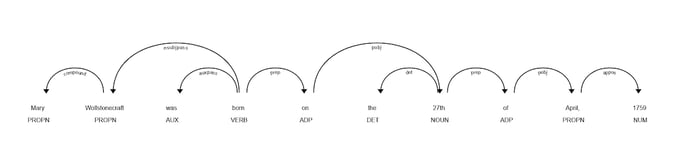
Source: GitHub
POS tagging
Part of Speech (POS) is a form of annotation, a method of describing and evaluating a word's grammatical function. In NLP, POS is an essential part of text interpretation.
To maximise NER's efficiency, you need to implement POS tagging. POS tagging is the process of assigning each word a part of speech, including nouns, pronouns, verbs, adjectives, adverbs, prepositions, conjunctions, interjections, and sometimes article determiners (definite vs. indefinite).
For example:
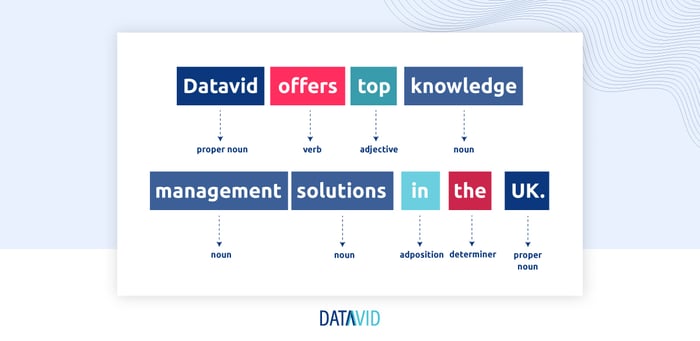
POS tagging is useful for information extraction, data analytics, machine translation, and many other purposes as part of NER.
Three blocks of the NER model
A typical named entity recognition model consists of three blocks:
- Noun phase identification is about identifying noun phrases in the text with the assistance of POS tagging
- Phrase classification is about classifying the identified noun phrases into pre-set categories.
- Named entity disambiguation is about linking a reference in the unit of text to a corresponding entity in a knowledge base to troubleshoot the misclassification of entities. In fact, entities are sometimes classified incorrectly. To avoid this, it is useful to create a level of validation on the results. For example, this can be done by utilising knowledge graphs.
Overall, the NER tool doesn't just classify and categorise different entities. It goes further to see how a word looks in the sentence and uses a statistical model to determine what type of noun it stands for.
Ideally, the training party should avoid entity ambiguity by providing the model with as many examples as possible to differentiate between similar entities.
The 2 most common NER models
Two types of NER models you may want to rely on are:
Type 1: Ontology-based NER
An ontology-based model relies on database lists to single out entities. Its accuracy depends on the relevancy of databases to the text it works with.
This model is usually applicable to medical, science, and research texts.
Type 2: Deep-learning NER
This more complex model uses various networks with millions of parameters to identify the semantic and syntactic relationships between words and phrases in the text.
The deep-learning NER model receives training on many databases and ensures better NER recognition than ontology-based models.
3 NER tools to consider
While many NER tools exist, they have different functionality.
Some of the common instruments include:
- Google Natural Language API
- TextRazor
- Dandelion
NER tool 1: Google Natural Language API
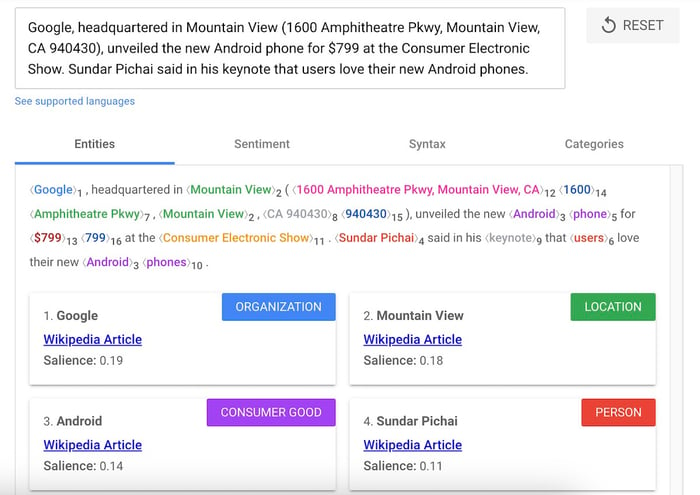
Source: Google Cloud
Google Natural Language API can analyze entities in standard documents and arrange custom entity extraction based on your needs.
This tool has excellent classification functionality but comes with a higher-than-usual price tag.
NER tool 2: TextRazor
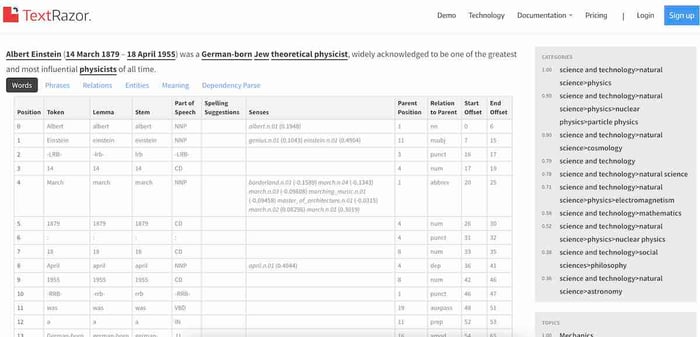
Source: TextRazor
TextRazor implements the deep learning model and analyses text by implementing many databases.
The tool offers precision and speed and works with 12 languages. With five different subscription tiers and a free trial, this tool can help you stay on budget.
NER tool 3: Dandelion
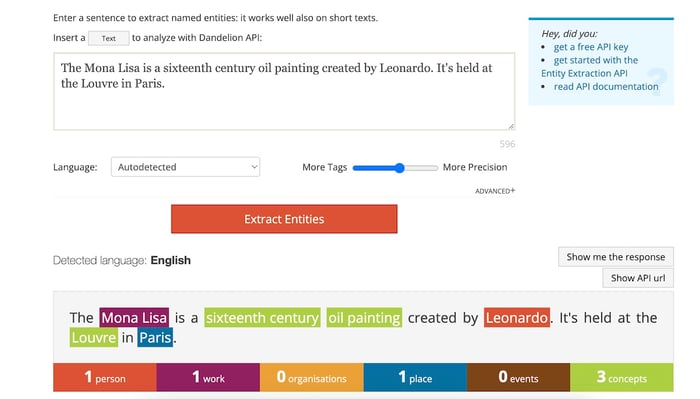
Source: Dandelion
Dandelion is a great NER tool for semantic search and semantic analysis. It works with seven European languages and offers an impressive latency of just 250ms. While it's more accurate than TextRazor, it's less precise than Google. There is a free tier, which can be sufficient for low analysis volumes (1,000 units daily).
Applying NER to your use case
By 2025, revenues from the NLP market are expected to reach $43 billion.
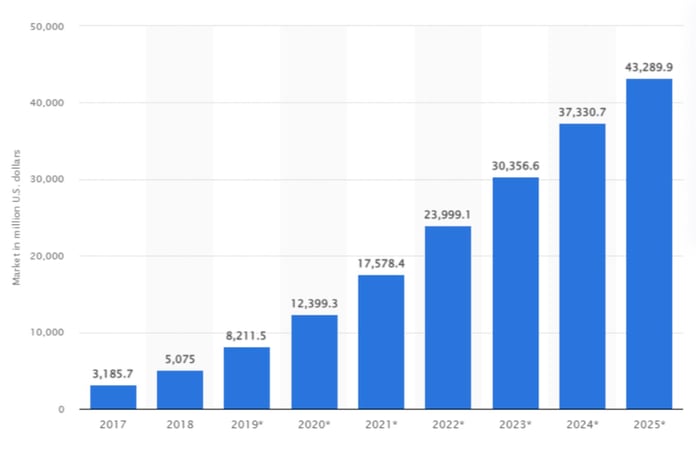
Source: Statista
In fact, NER is highly applicable in various aspects of business operations and scientific research.
NER generates valuable insights for educated decision-making by allowing you to identify and categorise critical elements in textual data.
Enterprises and SMBs all over the world are already using NER tools to achieve a variety of business goals:

- Recruitment
NER can help you scan many CVs and identify relevant candidates. Making such shortlists can take a significant burden off your HR staff and help them focus on revenue-generating tasks. - News updates
NER can help quickly identify key information from different channels. This can be highly helpful for businesses monitoring stock markets, technological updates, compliance changes, and much more. - Insurance claims
NER can help review insurance claims and identify key information instantaneously. - Customer analysis
NER can be used to analyse reviews, support tickets, survey results, and feedback. As a result, you can streamline your customer analysis and help identify opportunities for improving retention efforts. - Digital Marketing
NER can scan trending topics to help you find topics for your marketing content. - Medical
NER can help review patient information, test results, family history, statistics, and other data to identify important patterns.
NER can help filter out a vast amount of unnecessary information. To achieve top results, you need to invest time in model training or use pre-trained tools.
Leveraging named entity recognition tagging for your business
Named entity recognition is becoming an integral part of data processing. Considering the significant volume of information that a large company has to deal with, tagging and extracting important data is key to successful decision-making.
Leveraging the right NER tools can help you fully utilize this technology, cut data analysis time, and empower management to make better decisions.
Datavid Rover is a knowledge base engine that uses NER to identify, extract, and analyse data for your business needs.
Datavid Rover implements deep learning NER to ensure accurate and fast results.