7 minute read
In the vast realm of language, every word carries a unique story, a hidden narrative waiting to be revealed.
However, the complexities of human communication often entangle these narratives, leaving us in a net of ambiguity and uncertainty.
How do we decipher the true meaning of a word when it can represent different entities, each with its own meaning?
With named entity disambiguation (NED). It is a method to untangle language and reveal the real meaning of words based on contextual understanding and human cognition.
In this blog post, we will tackle the topic of named entity disambiguation (NED).
What is named entity disambiguation (NED)?
Named entity disambiguation is a natural language processing technique that aims to resolve the ambiguity that arises from named entities in text.
It comes into play after or during – depending on the approach - the named entity recognition process (NER), in which named entities are recognised and classified.
Named entities refer to specific objects, such as people, locations, organisations, dates, and other proper nouns. However, many named entities can have multiple meanings or refer to different entities altogether, confusing the understanding of the intended context.
NED's task is to map a named entity to other occurrences of the same entity in a knowledge base.
For example, consider the sentence: “Apple was the brain-child of Steve.”
How can a computer know if the entity “apple” refers to the fruit or to something else (as in this case, a company)? That's NED's responsibility.
NED should remove the uncertainty surrounding a named entity to ensure that the appropriate meaning - in this case, Apple as the company - is identified. It also adds knowledge of a specific entity (e.g., Apple), improving identification accuracy in the candidate selection phase.
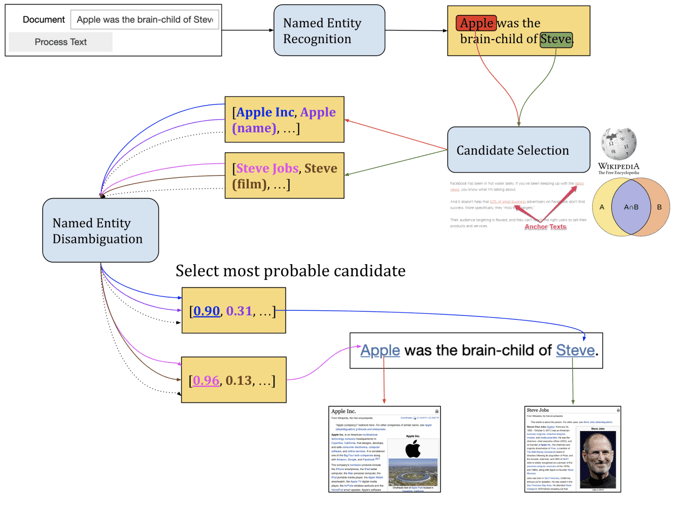
Source: Harvard study
What is named entity recognition (NER)?
Named entity recognition appears at the beginning of NLP pipelines. It identifies named entities in incoming data and classifies them into predefined categories, as shown in the following image.
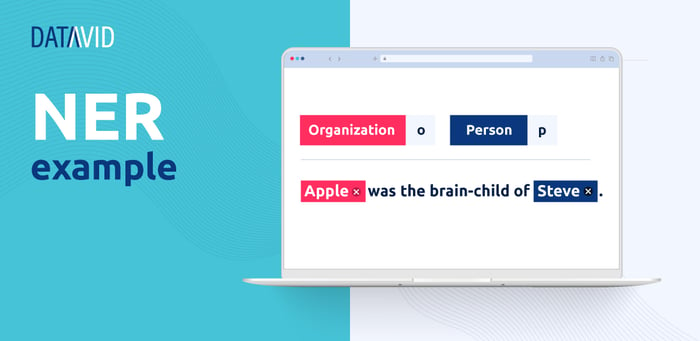
NER works to identify and categorize named entities, but it struggles to classify multi-category text, which is where NED comes into play.
NED works to establish the specific category and meaning of the entity; it finds out which knowledge node the multi-category entity belongs. It adds information to the knowledge base to improve future selections.
Although data scientists can create individualised datasets, most rely on existing sets to establish and train natural language processing applications.
NED in NLP pipeline
NED is part of the natural language pipeline that begins with recognition and ends with named entity linking (NEL).
- Recognition (NER)
Applications are programmed to look for named entities in text, identify them, and assign them a category.
- Disambiguation (NED)
Algorithms look at the named entities to determine the specific meaning of the entity referenced. - Linking (NEL)
Software links the text to a node in a knowledge base that references the specific named entity.
3 different NED approaches
NED approaches can be divided into the following three categories:
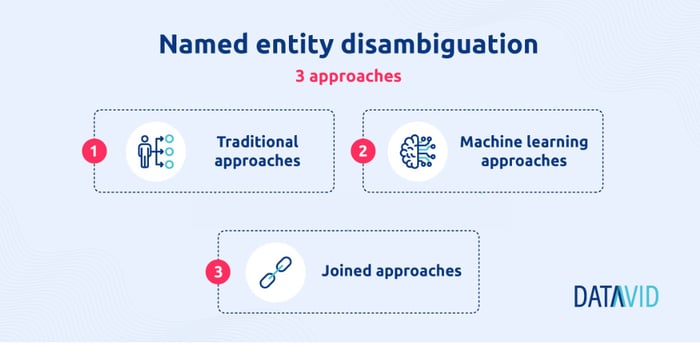
Traditional approaches
NED studies often use rules to calculate the similarity between the mentioned named entity and possible matches. Each mention is disambiguated using semantic similarities.
A confidence value combines application-specific rules that examine text descriptions from other datasets and the context of the entity mentioned.
The candidate with the highest score is assumed to be the named entity. If the entity is mentioned multiple times in the same text, this approach will not use the information in its calculation.
Because each mention is assessed individually, the program is unaware of other instances.
A collective approach uses the same semantic similarity rules but considers all mentions of a named entity in a given text.
Machine learning approaches
Rule- or dictionary-based techniques do not establish relationships among mentioned entities—they apply rules and assign a confidence score for every named entity.
With machine learning (ML), the application learns from the data it processes.
While ML may begin by looking at semantic similarities, the process quickly expands to include connections acquired through ingesting data.
It may represent these relationships through knowledge graphs as well.
Knowledge graphs display relationships using nodes, edges, and labels. Named entities are nodes, and the connections among nodes are called edges. Labels are attributes that help define relationships.
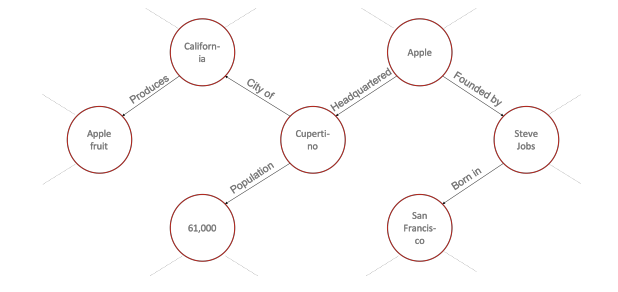
Source: Harvard study with Wikidata dataset (reference sentence: “Apple was the brain-child of Steve”)
Joined approaches
Tradition separates NER and NED when processing named entities; however, combining named entity recognition and disambiguation increases precision by sharing categories and confidence scores. Sometimes, NER or NED are used to represent both processes.
Using a shared dependency model, NED can use NER's outputs to establish links. Similarly, NED's ability to disambiguate named entities can refine the initial named entity recognition.
Together, they can deliver more efficient results.
What are the challenges?

Some of the common challenges facing NED are:
- Ambiguity. The same term can refer to different entities, depending on the context. This is because of polysemous names (i.e., having multiple meanings). As we mentioned before, the term "apple" can mean both a fruit and a company.
- Incomplete data. NED systems may have difficulty identifying a particular entity because the input text is too small or only contains a few occurrences of the named entity.
- New named entities. Dictionary.com added 313 new words to its lexicon, revised 1,140 definitions, and added 130 new meanings. That doesn't include new named entities that may appear on social media or in headlines. NED systems need a way to handle new entries.
- Name variations. Language allows us to be imprecise and incorrect. NED processes should account for spelling variations or mistakes, abbreviations, and multiple titles for a single entity. For example, the Windy City is another name for Chicago.
- Training data. Most training datasets are small, limiting supervised learning.
- Speed and scale. Speed is essential to search engines and bots, which requires NED systems to respond quickly regardless of the size of the knowledge base or the document. Scaling to include comprehensive datasets can slow execution time.
While data scientists and engineers continue to refine the processes that support NLP, many industries already use NED.
How is NED Used?
One of the most common uses of NED is search engines. For example, Google's search engine uses NED to return relevant search engine results over 8.5 billion times per day.
While search engines provide helpful information, they are not always efficient in returning the information your business needs. Ontologies often hold this information.
NED and ontologies
NED solutions are often supported by ontologies. They include information about entities, such as people, places, organisations, and concepts, and their relationships. Semantic search can exploit this knowledge to recognise and disambiguate entities mentioned in user queries, resulting in more accurate search results.
Ontologies play a crucial role in enabling semantic search by providing structured and standardised knowledge representations. Through semantic search, ontologies facilitate more precise and context-aware information retrieval.
Other key functionalities of ontologies in the context of semantic search are:
- Conceptual understanding: Ontologies define a hierarchy of concepts and relationships, enabling semantic search engines to understand the meaning and context of user queries. This understanding enables a better match between search queries and relevant information.
- Query expansion: Ontologies can expand user queries by identifying related concepts and terms. By incorporating these expanded queries, semantic search engines can retrieve more complete and relevant information that may not have been explicitly mentioned by the user.
- Contextual search: ontologies provide contextual information that can be used to refine search results based on user preference, location, time, or any other relevant factor. Semantic search engines can exploit this contextual knowledge to provide more customized and tailored search results.
- Faceted search: ontologies often define properties and attributes associated with concepts. Using these properties, semantic search engines can enable faceted search, allowing users to refine search results based on specific attributes or criteria, such as price, size, location, or category.
- Semantic similarity and classification: Ontologies provide semantic relationships between concepts, enabling semantic search engines to calculate the similarity between query terms and indexed content. The similarity calculation can be used to rank search results according to their relevance to the query, resulting in a more accurate and meaningful ranking.
- Integration of heterogeneous data sources: Ontologies can be a common vocabulary for integrating and harmonising data from different sources. Semantic search engines can exploit ontologies to bridge the gap between different data formats and sources, enabling users to search and retrieve information seamlessly across multiple repositories.
NED in industries (with examples)
Customised NED solutions can give organisations access to information hidden across their enterprise. Take, for example, the following industries.
Insurance
Determining the risk of insuring shipping vessels requires data on shipping routes and port conditions, as well as accidents at sea. Although large disasters such as the Ever Given make headlines, smaller claims can impact an insurer's bottom line.
Using NED, insurers can search for the right port name. For example, the Ports of Los Angeles (LA) and Long Beach are part of a shared marine complex, but each city is responsible for port operations. Disambiguating the named entities requires knowing that the Los Angeles World Cruise Center is part of the Los Angeles port and which terminals belong to Long Beach vs LA.
Once the named entities are identified, NED can look for claims under a specified dollar value.
If one port has more claims than another, insurers can look at vessel rates using one or both ports. Adjusting the insurance premium can help offset the increased cost of claims.
Healthcare
Medical facilities have standard protocols for patient treatment that include recommended dosages of approved medications. With NED, hospitals can select a protocol and extract which drugs are prescribed. If only a few of the approved named entities are used, the hospital could reduce its inventory only to include those actually used.
Drug names can vary.
Similar drugs may use brand names, and generic medications often use the primary drug. Medical personnel may abbreviate names, requiring NED to disambiguate the named entities.
Once hospitals have the information, they can reduce inventory to only those being prescribed.
Wealth management
Brokerage firms can use NED to identify their exposure in a troubled market. For example, a firm might want to know how much capital is invested in a given company showing market weakness.
With NED, firms search existing data to determine their investment level across the enterprise.
Because investors may refer to companies differently, NED would disambiguate the named entity to ensure all references are included. With a clearly defined entity, enterprise-wide investment portfolios could be analysed to determine a company's total exposure.
If the firm invests small amounts across multiple offerings, it might fail to realise its risks.
With NED-based insights, the company can determine a course of action to minimise its risk.
Benefits of named entity disambiguation

There are several benefits to named entity disambiguation, including:
Improved accuracy of natural language processing (NLP) applications
By correctly identifying the intended meaning of named entities, NLP applications such as sentiment analysis, chatbots, and machine translation can be more accurate in understanding and interpreting text.
Better information retrieval
When performing information retrieval tasks, such as searching for documents or articles related to a particular entity, named entity disambiguation can help to filter out irrelevant results and return more precise information.
Enhanced data analytics
Named entity disambiguation can help data analysts identify patterns and relationships between different entities, such as individuals or organisations, and make more informed decisions.
Implementing NED in your business
As new techniques become available, NED will become more precise. Fewer false positives will occur, and organisations will become more confident in the technology.
As businesses realise the benefit of deeper data analysis, they will look for ways to enhance their analytic capabilities in the following ways:
- Help marketing identify competitor behaviour to inform their strategies,
- Enable purchasing to locate alternative parts at lower prices,
- Create search engines that give researchers deep, contextual answers.
Because your data separates you from the competition, a closer relationship between the semantic layer and data means leveraging your information to find meaningful connections that turn into actionable insights. Those insights will provide your competitive edge.