

6 minute read
Two of the myriad innovations in the digital world stand prominently: Language Learning Models (LLMs) and Knowledge Graphs (KGs). These are more than trendy terms; they revolutionise our data processing and comprehension approach.

Consider LLMs your linguistically gifted buddies. They have a knack for understanding and generating human-like speech. Picture a scenario where conversing with your computer yields surprisingly coherent and relevant responses. That's the magic of Large Language Models.
Then, there are Knowledge Graphs, the meticulous organisers of the data world. They methodically categorise vast amounts of information, making your search for specifics as smooth as a walk in the park.
Here's where it gets fascinating: when Large Language Models and Knowledge Graphs team up, it's akin to having an ultra-intelligent aide who's not only a whiz at locating information but can also discuss it in everyday language.
This blog will explore the inner workings of LLMs and KGs. Let’s uncover the hype!
LLMs: The cognitive sponge
At its core, a Language Learning Model is like a sponge that soaks up language from vast oceans of text.
Imagine a diligent student reading and summarising books their whole life, developing an uncanny ability to generate summaries, answer questions, and create new stories. That student is your LLM.
This student, just like any other student, sometimes gets things wrong. It might confidently present a fabricated fact as truth, a phenomenon known as "hallucination”. It's like a well-intentioned friend who confidently states myths as facts to fill gaps in their knowledge.
This is where knowledge graphs come into play.
Think of them as an organised library, where every book, article, and note are connected by genre and the relationships between their content.
When LLMs tap into knowledge graphs, it's like giving our students a reliable reference guide. Instead of making guesses, they can verify facts, making their responses swift and accurate.
Getting to grips with Knowledge Graphs
Let's shift gears and dive into the world of knowledge graphs, using an analogy that’s as familiar as organising a massive library.
Imagine each book represents a piece of information. Instead of arranging these books solely by genre or author, we categorise them based on their relationships and relevance to each other.
This is the essence of knowledge graphs: a sophisticated system connecting dots of data, making it easier to find a book and the whole narrative you seek. 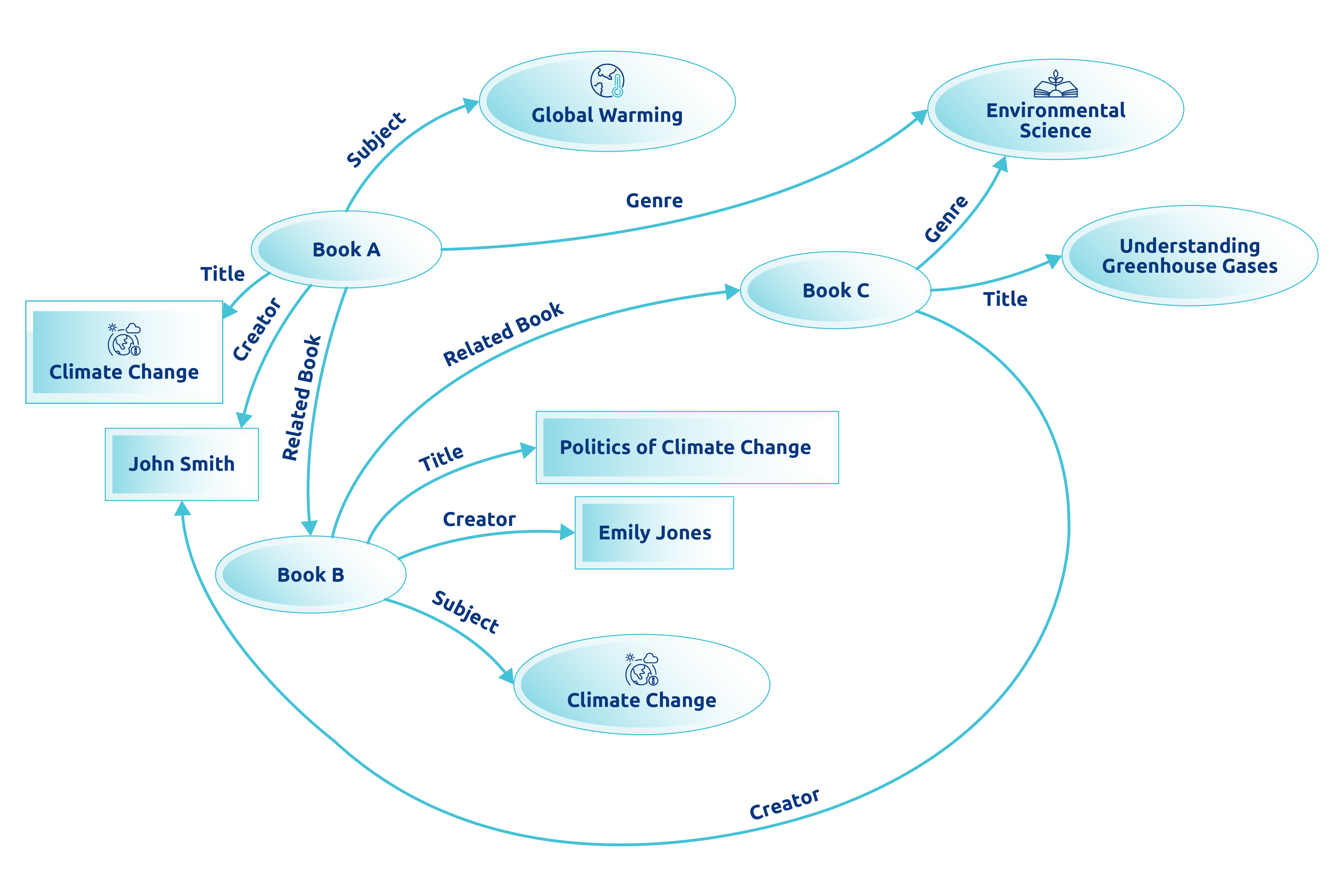
Knowledge graphs excel in structuring data, employing Natural Language Processing (NLP) to understand and organise information in ways that reflect how humans think and inquire.
Consider Resource Description Framework (RDF) and semantic ontologies as the blueprint and rules for managing this library.
RDF outlines the relationships between data pieces, like linking books by themes or concepts.
At the same time, semantic ontologies provide a structured vocabulary, ensuring that when you ask for books on "global warming," you get everything related, including climate change, greenhouse gases, and environmental policy.
This is the power of knowledge graphs: they transform isolated data points into a cohesive, navigable web of knowledge, ready to enhance our understanding of the world.
Integrated Intelligence: KGs + LLMs
The real magic happens when Large Language Models and knowledge graphs join forces. It fundamentally shifts the landscape for enterprises and data search capabilities.
Firstly, integrating LLMs with knowledge graphs enables enterprises to leverage the depth and breadth of their data in unprecedented ways.
With their ability to understand and generate human-like text, LLMs bring a layer of intelligence that can interpret complex queries in natural language.
When paired with the structured, interconnected data of knowledge graphs, this combination allows for more precise, context-aware search results. Users can ask complex questions and receive answers that are not only relevant but also enriched with insights drawn from the vast, interconnected data.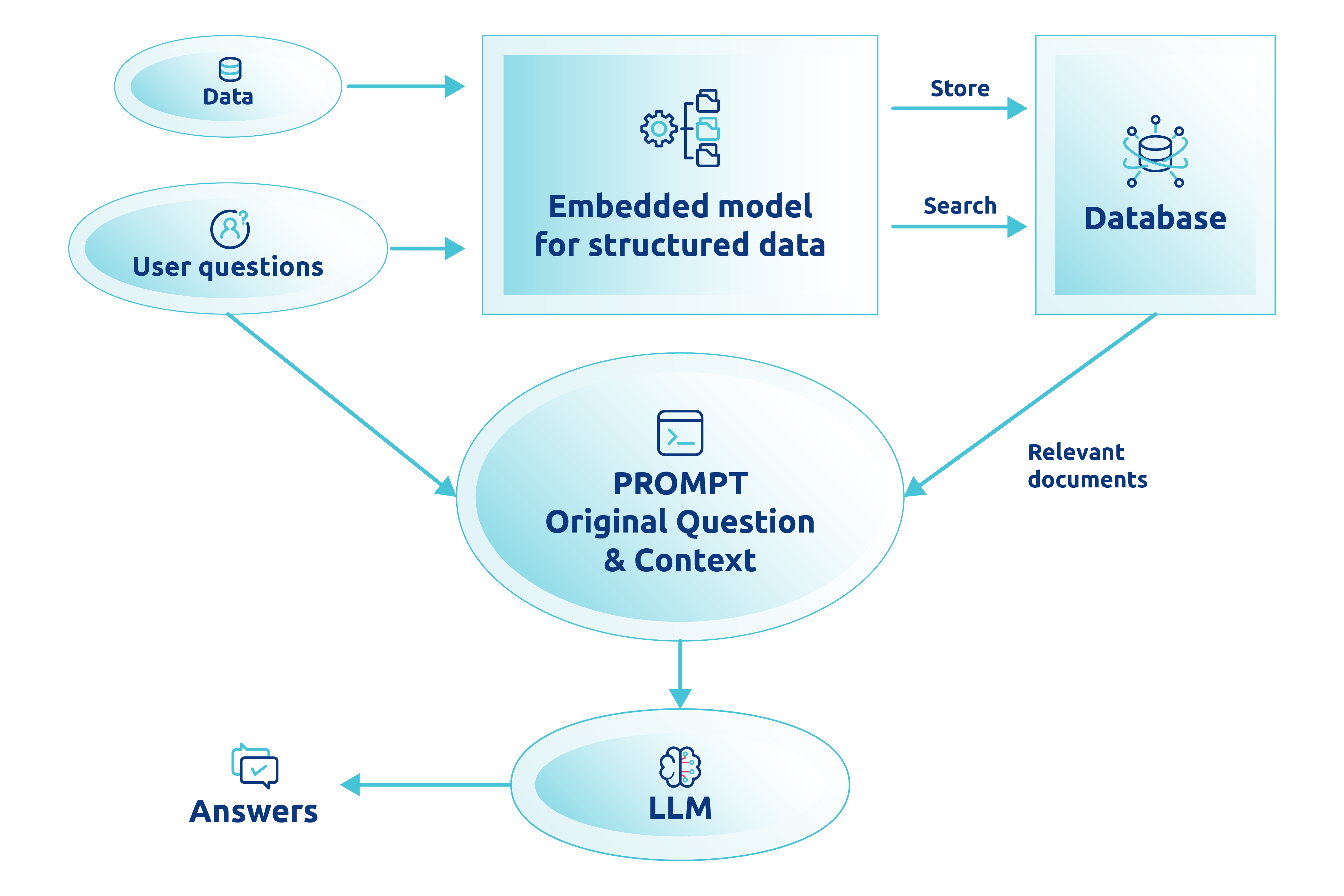
One of the critical technologies facilitating this integration is the Retrieval-Augmented Generation (RAG) model.
RAG combines the best of both worlds: the generative capabilities of LLMs to produce coherent, contextually relevant text and the retrieval capabilities of knowledge graphs to source accurate, specific information.
This means that when a query is made, the system doesn't just generate an answer out of thin air; it retrieves pertinent information from the knowledge graph and then uses the LLM to contextualise and articulate it comprehensibly.
Another critical aspect of this integration is the use of vector text embedding. This technique transforms text into numerical vectors, enabling the system to understand and match the semantic meaning of queries with the relevant data points in the knowledge graph.
Through vector embeddings, LLMs can more effectively interpret the nuances of human language, leading to search results that are significantly more aligned with the user's intent.
For enterprises, this integration means transforming their vast data reservoirs into accessible, actionable insights. It makes search efficient and intelligent, capable of understanding the intricacies of human queries and providing precise and contextually enriched answers.
Achieving this integration, however, requires a sophisticated understanding of both technologies and a strategic approach to melding them into a cohesive system.
It's not just about having vast amounts of data or the most advanced models; it's about cultivating a symbiosis where each component magnifies the strengths of the other, leading to a solution far greater than the sum of its parts.
Fine-tuning the fusion to specific domains
Maximising the integration of LLMs with knowledge graphs requires tailoring to the domain's specific needs, involving key steps for total potential leverage.
- Understanding domain-specific requirements: Initially, it's vital to comprehend the domain's unique requirements, terminologies, and data structures, such as the healthcare sector's complex terminologies and privacy regulations.
This involves collaboration with domain experts to ensure the knowledge graph accurately reflects the field's nuanced relationships and terminologies. - Entity Linking: The Named Entity Recognition (NER) techniques extract entities from unstructured text and link the entities to corresponding entities in the KGs: involving entity resolution and disambiguation to ensure accurate linking.
- Customising the Knowledge Graph: Creating a domain-specific knowledge graph involves integrating data from diverse sources to cover the domain's knowledge breadth while maintaining accuracy and relevance.
This step uses advanced NLP techniques to organise information according to the domain's structure. - Knowledge Base Completion: This refers to utilising LLMs to predict or infer missing information based on the existing data in the KG. It generates plausible completions or suggestions for missing entities or relationships
- Training the LLMs: The Large Language Model is trained on domain-specific datasets to grasp the field's linguistic nuances, ensuring proficiency in domain language and the ability to handle nuanced queries typical in the field.
- Iterative refinement: The integration is an ongoing process. It requires continuous monitoring and updates to the LLMs and the knowledge graph based on user feedback and new information, ensuring they stay relevant to the domain's latest developments.
This customised approach guarantees that enterprises fully harness these technologies, transforming their information access, interpretation, and utilisation for enhanced decision-making and innovation.
Evaluating the integration success
Accuracy and relevance: The system's success is primarily measured by the accuracy and relevance of its responses to user queries, aiming for a high degree of precision and recall validated against expert benchmarks.
Speed of information retrieval: Efficiency is gauged by the time it takes to deliver relevant information, to reduce the search duration significantly compared to traditional methods.
User satisfaction: User feedback, engagement levels, and adoption rates are direct indicators of the system's value, gauged through surveys and usage analytics.
Impact on Decision-Making: The broader organisational benefits, such as improved decision accuracy and efficiency, highlight the system's contribution to achieving strategic goals.
These metrics are not just bound to LLM and KGs Integration, they need to be taken care of in any and every aspect of providing solution to enterprises dealing with data.
Datavid ensures that the solution not only meets immediate user needs but also supports continuous improvement and scalability. Have a look at how enterprises achieve continued success with Datavid's expert data services and solutions.
Practical implementations and use-cases
Integrating Language Learning Models and knowledge graphs significantly enhances data accessibility and operational efficiency across industries.
This approach streamlines research, reduces redundancy, and saves valuable time and resources by providing precise, context-aware search capabilities.
Enterprises leveraging this integration can rapidly transform vast, unwieldy data collections into a streamlined, searchable knowledge base, facilitating quicker decision-making and fostering innovation.
Explore Datavid’s Rover, a prime example of these technologies in perfect harmony.
It is an extensible data platform designed to help you extract knowledge from varied data sources by classifying real-world concepts automatically, building rich knowledge graphs, running natural language searches, and uncovering previously unavailable insights.
The bigger picture and prospects
The fusion of Language Learning Models and knowledge graphs represents a significant leap forward in our quest to make technology more intuitive and responsive to human needs.
Through this integration, we're not just improving data search capabilities; we're redefining how we interact with digital information, making it more accessible, insightful, and, ultimately, more valuable.
Datavid is a company that provides solutions to help businesses take advantage of the latest technologies and transform their data landscapes.
By simplifying complex data and making it easier to understand, Datavid enables enterprises to gain new insights, drive innovation, and make more informed decisions faster and with greater confidence than ever before.
As we look ahead, the future of LLMs and KGs appears promising. These technologies are constantly evolving and getting more advanced, so we will likely see even more sophisticated integrations in the future.
This will lead to significant advancements in artificial intelligence, machine learning, and beyond.
The potential applications for these technologies are vast and varied. They can enhance decision-making processes, automate complex tasks, and create more personalised and engaging digital experiences.



