

3 minute read
Data ingestion is vital and can be achieved through different patterns. Understanding these patterns is essential to supporting the development of business-critical applications.

Data ingestion is a critical technology for all classes of businesses and organisations.
As the world increasingly produces data at various levels of complexity and volume, there has to be a way to extract more value from it.
To achieve this aim, technology providers must use various types of data ingestion patterns. Let’s examine five data ingestion patterns that are absolute boons for modern app development.
Data ingestion pattern #1: Point-to-point
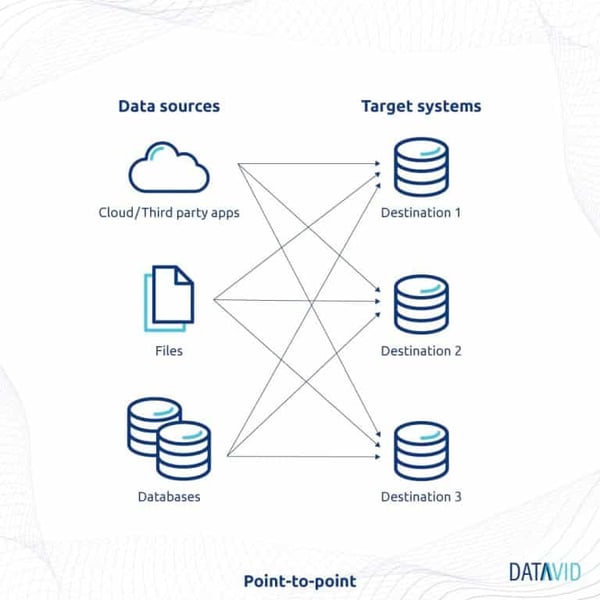
Point-to-point data ingestion establishes the direct connection between the data’s source and its target.
In this pattern, the changed data is moved without causing interference to the database workload. It is also referred to as a real-time data ingestion pattern.
Data is ingested in real time.
Finds applicability in time-sensitive use cases.
The data ingestion pipeline in this pattern allows for rapid operational decision-making based on current data. Because of its simple architecture, it is the most implemented pattern by most enterprises.
Data ingestion pattern #2: Hub and spoke
The hub and spoke data ingestion pattern has the source and target decoupled. Here, data ingestions only travel within the hubs.
These are then responsible for managing connections and performing data transformations.
This pattern minimises the frequency of data ingestion connection, allowing for a simplified operational environment.
It suits most applications where requirements frequently change in an operational environment. The downside of this pattern is that it is limited in size.
A hub is logical, and therefore vast enterprises may face challenges with performance and latency using this approach.
Data ingestion pattern #3: Batching
The batching data ingestion pattern focuses on collecting data and then transferring it in batches.
Batches are sent according to set schedules but not immediately.
The ingestion layer of this pattern can be set to collect data in response to trigger events, simple scheduling, or other types of logical ordering.
When crafting such a system, it must support scaling to process data at peak volumes.
Data ingestion pattern #4: Lambda
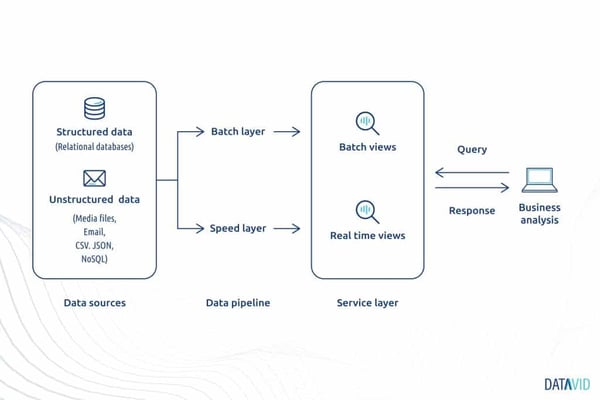
Lambda data ingestion pattern incorporates both the point-to-point and batch ingestion methodologies.
It is highly desirable for its ability to provide broad views of the batch data.
This pattern can give you the viewpoints you need when you need time-sensitive data.
It achieves its abilities by allowing three different configurations:
- Batch;
- Serving, and;
- The speed layer.
The first two index the available data in batches, whereas the third indexes data that the first two configurations haven’t picked up.
A continuous hands-off between the three configurations allows minimal latency.
Data ingestion pattern #5: Sharding
The sharding pattern relies heavily on the software architecture you have available. It results in a datastore separated from single storage instances known as shards.
As data is ingested, it is divided up to fulfil some sharing logic.
When attempting to look up data, queries are performed against these shards.
Sharding is a superb data ingestion pattern for large, distributed applications, as it permits quick execution of commands and questions.
Which data ingestion pattern to consider
Deciding appropriate data ingestion is critical for any enterprise to make sense of ever-increasing data.
A real-time data ingestion pattern is simple to implement and suitable when insights from data are required almost in real-time.
When requirements are changing rapidly, the hub-and-spoke pattern should be given consideration.
The batch data ingestion pattern is the most appropriate for large enterprises where data sources comprise legacy systems.
The best approach to handling variety, velocity, and volume is to leverage the lambda pattern. When an ecosystem comprises distributed applications, sharding data ingestion patterns are considered.

A knowledge engine like Datavid Rover lets you connect your data across different cloud providers, such as AWS buckets, Microsoft Sharepoint, and more.
The best part is that you can easily extract valuable insights from the data while ingesting it all through the program’s simple user interface.



