11 minute read
Quick answer: GraphRAG combines knowledge graphs with retrieval-augmented generation to ground AI in verified life sciences data. For Chief Data Officers in pharma, biotech, and scientific publishing, it's the pattern that turns stalled AI pilots into auditable, scalable production systems backed by traceable, citation-level evidence.
If you're a Chief Data Officer in life sciences, you've likely already approved one or two AI pilots that looked promising in the demo and stalled the moment QA, regulatory, or research leadership asked the obvious question: where exactly did this answer come from?
That gap, between fluent output and defensible evidence, is why so many GenAI investments stall before production. Audit reviewers won't sign off on document-level citations, research teams keep duplicating cross-source evidence work, and CSR, signal triage, and target prioritization timelines drag because evidence assembly is still manual.
The pattern that worked in the demo quietly fails to scale.
GraphRAG for life sciences is the hybrid AI pattern that closes that gap. It pairs a domain knowledge graph with retrieval-augmented generation, so large language models reason over verified, connected enterprise knowledge rather than flat text chunks.
This article is written for CDOs evaluating whether GraphRAG belongs on the data and AI roadmap, covering what good looks like, where the value sits, and what evaluation criteria to apply before committing pilot budget.
At a glance
- GraphRAG grounds LLMs in a verified knowledge graph, making outputs explainable, auditable, and defensible to QA, regulatory, and audit reviewers.
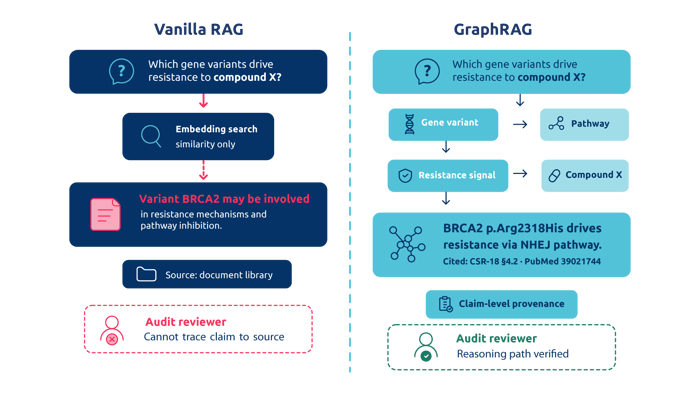
- Vanilla RAG's flat embeddings collapse synonyms, identifiers, and multi-hop scientific questions, which is why so many life sciences AI pilots underperform and stall.
- A production GraphRAG stack rests on three layers: an ontology-backed knowledge graph, hybrid retrieval, and governed generation. Cutting any one layer compromises trust at scale.
- The highest-impact use cases include target identification, drug repurposing, CSR evidence assembly, pharmacovigilance signal triage, and research discovery across siloed corpora.
- Buying decisions should rest on five criteria: data readiness, governance maturity, integration footprint, security and compliance posture, and pilot scope discipline.
- The best pilots start narrow, with one anchor use case, a six to eight week scope, and a clearly defined business outcome you can measure.
What GraphRAG means in a life sciences context
GraphRAG is a hybrid AI pattern that pairs a domain knowledge graph with retrieval-augmented generation, so large language models reason over verified entities and relationships rather than flat text chunks.
In life sciences, that graph encodes the things that actually matter to scientific and regulatory work: genes, proteins, diseases, compounds, trials, authors, institutions, and the ontologies linking them.
The pattern rests on three layers working together. The knowledge graph layer captures domain entities and relationships, aligned to established ontologies like MeSH, SNOMED CT, MedDRA, and UMLS.
The retrieval layer blends graph traversal, vector search, and keyword lookup so each part of a question reaches the right mechanism. The generation layer uses the LLM to fuse retrieved subgraphs and passages into coherent, citation-backed answers.
 To be clear, this article is about GraphRAG for life sciences in pharma, biotech, clinical research, agriscience R&D, and scientific publishing. It's not about EHR-centric healthcare operations, care coordination, or patient-facing clinical systems. Don't inherit assumptions from healthcare IT discussions that don't apply.
To be clear, this article is about GraphRAG for life sciences in pharma, biotech, clinical research, agriscience R&D, and scientific publishing. It's not about EHR-centric healthcare operations, care coordination, or patient-facing clinical systems. Don't inherit assumptions from healthcare IT discussions that don't apply.
Why traditional RAG falls short for life sciences data
The case for GraphRAG life sciences becomes clearest after watching a vanilla RAG pilot underperform. The pattern repeats across pharma and publishing: a research team asks a question that requires connecting evidence across systems, and the system returns a confident-sounding but shallow answer that won't survive review.
Picture a common failure mode. A researcher asks which investigators collaborated across CRISPR and oncology studies at a specific set of institutions. The system returns three pages of prose about CRISPR mechanisms.
Semantic similarity found documents on the topic. It had no way to reason about the author network behind them.
Three structural reasons explain why flat RAG struggles in this domain:
- Heterogeneity beats embeddings. Life sciences data is full of synonymous gene names, multiple identifiers, controlled vocabularies, and shifting ontologies. Flat embeddings collapse those distinctions into averaged vectors, losing the precision scientific work needs.
- Biology is a network. Single-hop vector retrieval cannot traverse gene → protein → pathway → disease → compound questions. The answer lives in the relationships, not in any single document.
- Unstructured content at scale needs structure. Publications, clinical study reports, patents, slide decks, interview notes, and lab notebooks hold most of the value. Without structured grounding, an LLM drifts toward fluent-sounding but unreliable output.
There's a final issue that matters most to data leaders accountable for trust. Document-level citations aren't enough when a reviewer asks where exactly the evidence for a claim lives. They need claim-level provenance and a traceable reasoning path.
Embedding-only RAG cannot provide that. This is where graph retrieval augmented generation life sciences patterns earn their keep. Proper RAG for life sciences AI links every generated statement back to a specific node, edge, or source paragraph.
That's what LLM grounding life sciences workloads actually requires, and it's the difference between an AI investment that scales and one that gets quietly shelved.
Vanilla RAG vs GraphRAG: a CDO decision lens
You don't need to debate retrieval algorithms to make this call. The question is which pattern produces evidence the business can defend, scale, and govern.
The table below frames the comparison the way a data leader actually evaluates it.
|
Decision dimension |
Vanilla RAG |
GraphRAG |
|
Trust in output |
Plausible-sounding answers with document-level citations |
Claim-level citations tied to specific nodes, edges, and source paragraphs |
|
Multi-hop reasoning |
Limited; single-hop similarity only |
Native; graph traversal across entities and relationships |
|
Handling of synonyms and identifiers |
Collapsed into averaged vectors |
Resolved through ontology alignment (MeSH, SNOMED CT, MedDRA, UMLS) |
|
Audit and regulatory defensibility |
Weak; reviewers can't trace claims to source |
Strong; designed for GxP, FDA, EMA evidence trails |
|
Scalability across use cases |
Each new use case re-builds retrieval logic |
Knowledge graph compounds in value; reused across use cases |
|
Risk of hallucination on critical questions |
High in regulated workflows |
Materially reduced through grounded, deterministic retrieval |
|
Governance enforcement |
Application-layer only |
Enforced at retrieval time through role-based, permission-aware queries |
|
Time to durable value |
Quick demo, slow to production |
Slightly longer to first pilot, but production path is clearer |
The strategic point: GraphRAG is not just a more accurate retrieval mechanism. It produces an asset, the knowledge graph, that outlives any single AI project and becomes a reusable foundation for the next one.
How GraphRAG works across the life sciences data stack
Think of graph retrieval augmented generation life sciences as a three-layer pattern: a semantic foundation, a hybrid retrieval engine, and a governed generation step. Each layer is load-bearing. Cut one and the quality of the output degrades in ways that matter for science and regulation.
Here's what each layer does, and what to get right.
The semantic foundation: ontologies and the knowledge graph
Start by modeling your domain explicitly. Entities are the things you reason about: genes, proteins, targets, diseases, compounds, trials, publications, authors, institutions. Relationships are what connects them: TREATS, TARGETS, ASSOCIATED_WITH, IN_PIPELINE, WROTE, HAS_MESH_TERM.
Align the graph to established ontologies rather than inventing vocabulary. MeSH, SNOMED CT, MedDRA, and UMLS already do the hard work of standardizing concepts.
Every extracted fact should carry a pointer back to its source document and paragraph, so explainability is built in rather than retrofitted later. This is the foundation Datavid's knowledge graph design and build work centers on.
Hybrid retrieval: graph, vector, and keyword
Different questions need different retrieval mechanisms. A production stack blends three of them:
- Graph traversal for multi-hop structural questions: collaborators, gene-disease-compound chains, referral networks, mechanism-of-action pathways.
- Vector search for semantic similarity: "what does this paper say about X," "find passages conceptually close to this query."
- Keyword search for exact matches: specific compound names, trial IDs, regulatory codes, assay identifiers.
A retrieval orchestrator routes each part of a question to the mechanism best suited for it, then fuses the results into one ranked set of evidence.
Grounded generation with tool-calling
The final layer constrains the LLM. Rather than letting the model generate free-form database queries, the architecture exposes a curated library of tools the LLM can call. Each tool runs a deterministic, reviewed query against the graph and returns structured results.
The LLM's job is to decide which tool to call, not to invent Cypher or SPARQL on the fly. It then fuses structured graph output with retrieved text into a coherent, citation-backed answer. This separation is what makes GraphRAG safe to deploy against regulated data.
Where GraphRAG delivers value in life sciences
GraphRAG is not a single application. It's a pattern that pays off wherever connected scientific evidence drives a decision.
For CDOs, the question isn't whether the technology works, it's where GraphRAG life science data investments produce the strongest combination of business impact and audit defensibility.
Target identification and biomarker discovery
Early R&D teams spend weeks reasoning across gene-disease-pathway-compound relationships to prioritize targets.
A graph-backed retrieval pattern lets them ask multi-hop questions like: which targets are implicated in disease X, supported by at least two independent datasets, and not already in a competitor's pipeline?
Organizations like Novartis and Roche have pursued biomedical knowledge graphs for exactly this kind of reasoning.
GraphRAG surfaces the connections between internal experimental data and the external literature that gives those findings meaning. For CDOs, the impact is measured in reduced duplicated research effort and faster prioritization decisions.
Drug repurposing and competitive intelligence
Repurposing depends on traversing mechanism-of-action graphs to spot compounds already approved for one indication that plausibly address another.
GraphRAG lets scientists follow "inhibits protein X → protein X implicated in disease Y" chains across millions of documents and structured datasets.
The same graph layer doubles as a competitive intelligence fabric, tracking pipelines, publications, patents, and regulatory filings as connected nodes rather than scattered text.
That gives strategy and portfolio teams an asset they can query directly instead of commissioning analyst work for every question.
Clinical study analysis and CSR summarization
Clinical Study Reports are long, structured documents that hide value behind sheer volume. GraphRAG extracts structured evidence from CSRs and links it to trial metadata, endpoints, adverse events, and population characteristics.
When a medical writer or reviewer asks a regulatory question, the system can answer with claim-level citations back to the source sections. That cuts hours off evidence assembly and leaves a defensible audit trail.
From a CDO's seat, this is one of the cleanest measurable wins, since the time savings show up directly in regulatory team workload.
Safety signal investigation and pharmacovigilance
Signal triage depends on connecting adverse event reports to compounds, populations, co-medications, and mechanisms.
A graph layer makes those connections explicit, and GraphRAG lets investigators ask natural-language questions such as: are we seeing a clustering of event X in patients with co-medication Y on compound Z?
Every answer carries a reasoning path a reviewer can follow. That matters when a regulator asks how a conclusion was reached.
Scientific publishing and research discovery
Publishers and research organizations sit on corpora of millions of articles. Datavid has worked on life sciences data platforms and publishing platforms with article counts in the tens of millions, including work with the American Chemical Society.
Entity-aware retrieval powered by a knowledge graph turns that corpus into a cognitive search layer. Researchers find what matters across previously siloed publications, internal notes, and external datasets, without being buried in keyword-matched noise.
Read our guide on how the semantic layer accelerates AI data readiness for more background on the foundation that this depends on.
What good looks like: evaluation criteria for CDOs
Before committing to a pilot, work through these criteria with your team and any external partner. They're the questions that separate vendors who can demo from teams who can deliver in regulated life sciences environments.
Data readiness
A GraphRAG pilot doesn't need clean enterprise data, but it does need a viable starting corpus. Look for a use case where two or three high-value sources can be ingested and aligned within the pilot window.
If the answer to "where does the evidence live?" requires a year of data engineering before a graph can be built, the scope is wrong.
Governance maturity
Ask whether your organization already has consistent vocabularies for the domain in scope, even informally. If terminology is fragmented across teams, the pilot needs an explicit ontology workstream, and that's normal.
What you want to avoid is a pilot that ignores governance and produces a graph nobody outside the project team trusts.
Integration footprint
Production GraphRAG touches your knowledge graph store, vector database, identity provider, document repositories, and existing search or analytics tools. A credible vendor will lay out integration points clearly and won't insist on rip-and-replace.
If a proposal requires you to abandon a strategic platform like Snowflake, MarkLogic, or Databricks to make GraphRAG work, push back.
Security and compliance posture
Confirm that role-based access is enforced at retrieval time, that audit logs capture every query and result, and that the partner holds credentials that match your environment.
Datavid's ISO 27001 and Cyber Essentials Plus certifications reflect the bar regulated clients should expect from any delivery partner working on this layer.
Pilot scope discipline
The fastest way to kill a GraphRAG program is to start with five use cases instead of one. Insist on a single anchor use case, a fixed time-box, and a measurable business outcome. Vendors who agree to that discipline usually deliver. Vendors who push for broader scope upfront usually don't.
Risks to plan for
GraphRAG is a strong pattern, but no architecture is risk-free.
- Ontology overreach. Trying to model the entire domain before delivering value is the most common failure. Ship the minimum ontology needed for the anchor use case, then extend.
- LLM over-trust. Even with grounding, the model can phrase a citation-backed answer in a way that sounds more certain than the evidence supports. Human-in-the-loop review on regulated outputs is not optional.
- Graph maintenance debt. A knowledge graph is a living asset. Plan for ongoing curation, ontology updates, and data lineage maintenance as part of the operating model, not as a follow-on project.
What a production-ready GraphRAG architecture looks like
The single most important principle: separate probabilistic reasoning from deterministic execution. The LLM handles what it's good at, which is interpreting questions and composing answers.
The graph and tool layer handle what they're good at, which is returning exact, reviewed results against regulated data. In pharma and life sciences, letting a model generate arbitrary database queries is not acceptable.
A production GraphRAG stack needs these components:
- Ontology and taxonomy layer aligned to industry standards (MeSH, SNOMED CT, MedDRA, internal controlled vocabularies).
- Knowledge graph store such as MarkLogic, Neo4j, or Ontotext, with persistent identifiers and metadata lineage.
- Hybrid retrieval orchestrator combining graph traversal, vector search, and keyword lookup.
- Curated tool library the LLM can call, rather than free-form query generation against production data.
- Role-based access control applied at query time, so retrieval itself is permission-aware.
- Observability, drift monitoring, and human-in-the-loop validation for outputs that touch regulated decisions.
Building this from scratch often takes 3 to 6 months of senior engineering time. Datavid Rover provides most of these components out of the box, which is how Datavid's GraphRAG services team delivers production pilots in 6 to 8 weeks instead.
Governance, explainability, and compliance built in
Every CDO eventually faces the same conversation with QA, regulatory, and audit: how do you defend AI-generated outputs to a reviewer? GraphRAG's structure gives you a clean answer, and that answer is increasingly what determines whether AI investments make it past pilot.
Explainability is a first-class output of the pattern. Every generated claim traces back to a specific graph node, relationship, or source paragraph. That's what regulators mean when they talk about audit trails and data lineage, and it's what GxP, FDA, and EMA reviewers look for when validating AI-assisted evidence.
The graph layer itself applies FAIR principles (Findable, Accessible, Interoperable, Reusable) to your knowledge foundation. That makes the asset durable beyond any single AI project and usable across teams, tools, and successor platforms, which is the kind of compounding return that justifies investment.
Role-based access and federated governance matter just as much. Retrieval should respect who is allowed to see what, enforced at query time rather than patched on at the application layer.
How to start a GraphRAG pilot in your organization
Most life sciences GraphRAG projects don't fail because the technology doesn't work. They fail because the starting scope was too broad. Narrow scope wins every time.
Use this short checklist to self-diagnose readiness:
- Do your teams regularly join data across three or more systems to answer a single scientific or regulatory question?
- Are your existing AI pilots plateauing because outputs can't be traced back to verified sources?
- Is your knowledge scattered across publications, CSRs, lab notebooks, and internal datasets with inconsistent vocabularies?
- Do you have at least one high-value use case where connected reasoning, not just search, changes the outcome?
If you answered yes to two or more, you're ready for a scoped pilot. Datavid's recommended path is a 6 to 8 week discovery-to-pilot engagement that delivers a working GraphRAG slice on one anchor use case before scaling.
That keeps budget predictable, gives stakeholders something concrete to evaluate, and proves the pattern on your real data before you commit to a broader rollout.
Want a structured way to evaluate GraphRAG against your own data and use cases? Book a free GraphRAG readiness assessment and walk away with a scoped pilot recommendation, an evaluation framework, and a clear view of where connected, explainable AI would create the fastest impact in your environment.