4 minute read
AI projects often fail not because of algorithms, but because of weak data foundations leading to untrustworthy models and unreliable insights.
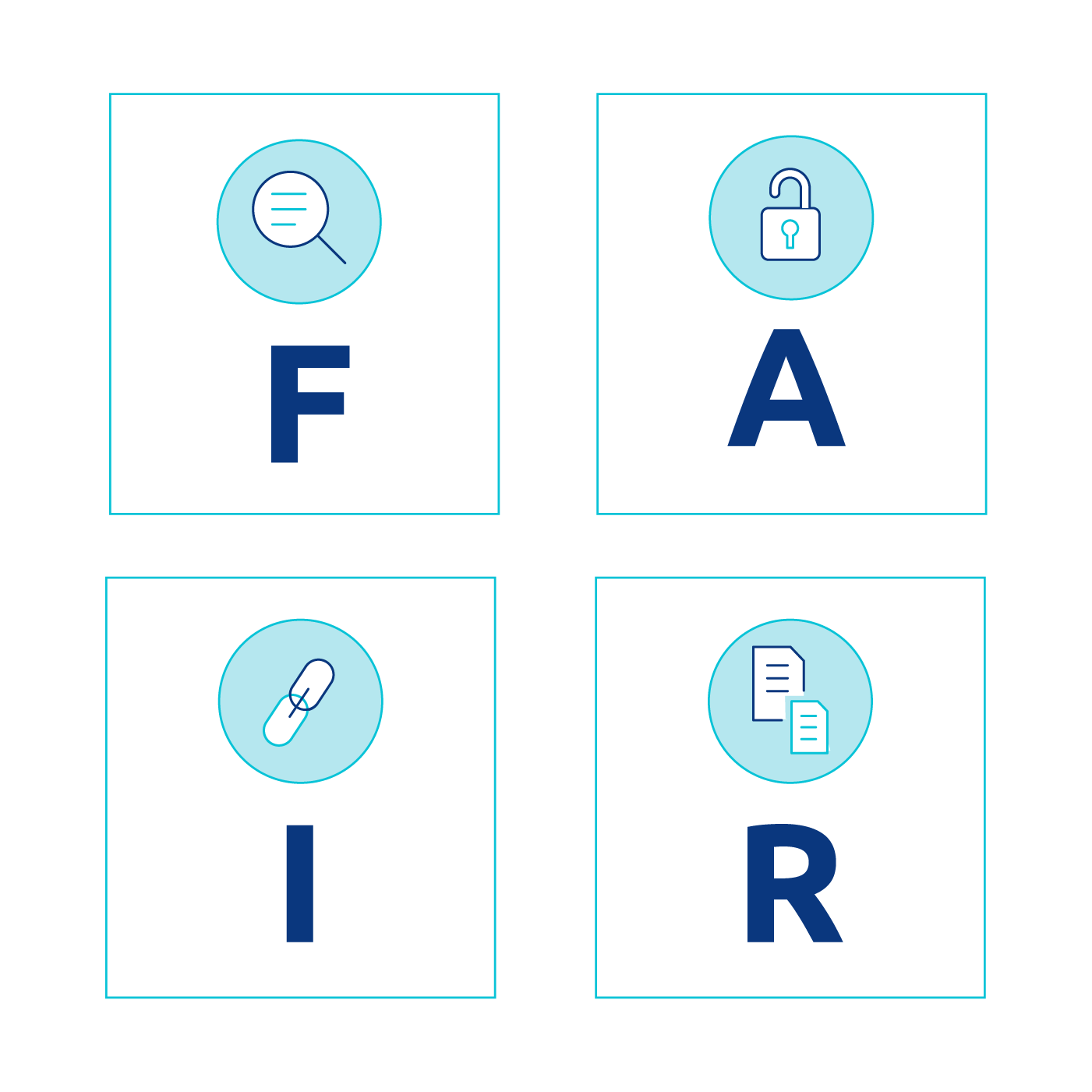
FAIR data principles (Findable, Accessible, Interoperable, Reusable) offer a proven framework to change that. Originally designed for scientific research, they have become the gold standard for building responsible, scalable AI.
By embedding FAIR into your data strategy, you can accelerate AI adoption, reduce project risks, and unlock measurable business value.
FAIR data principles: The secret to responsible AI adoption
When organizations attempt AI adoption without solid data foundations, the outcome is predictable: failed projects, untrustworthy models, and ‘insights’ that don’t hold up under scrutiny.
But there’s a better way. Organizations that anchor their AI initiatives in FAIR data principles achieve dramatically different results: data that’s discoverable, consistent, and auditable enabling AI models that are explainable, reproducible, and truly trustworthy.
The result? AI systems that deliver actionable insights and measurable business value at scale.
What are FAIR data principles?
FAIR is more than an acronym. It's a framework that transforms how organizations think about their data. Originally developed for scientific research, FAIR principles have become the gold standard for responsible AI and scalable data management.
FAIR stands for:
Findable – Rich, indexed metadata and persistent identifiers
Accessible – Standardized, governed access with security and SLAs
Interoperable – Common formats, schemas, and shared vocabularies
Reusable – Versioned, well-documented datasets with clear licensing
FAIR is powerful because of 15 guiding principles (F1–F4, A1–A2, I1–I3, R1–R1.3) are measurable and enforceable, aligning data quality, provenance, and interoperability to de-risk AI.

Let's break down what each means for AI adoption:
Findable
Making data discoverable for AI
The Problem:
Data scientists spend 80% of their time just finding and preparing data. In large enterprises, valuable datasets often exist but remain buried in silos or undocumented systems.
The FAIR solution:
Findable data is tagged with rich metadata (persistent IDs, and lineage make assets discoverable and traceable), catalogued, and searchable by both humans and machines.
Key implementation elements:
- Data catalogues with business glossaries and technical metadata
- Automated discovery of new data sources
- Lineage tracking for data flow visibility
- Tagging and classification searchable by business context
Impact:
A global retailer implemented comprehensive data cataloguing, reducing their AI project startup time from 6 months to 6 weeks. Data scientists could quickly identify relevant customer, product, and transaction data without manual detective work.
Accessible
Right Data, Right People, Right Time
The Problem:
Even when data is findable, gaining access can require lengthy approval chains, or manual data exports or brittle custom integrations.
The FAIR solution:
Accessible data uses standardized interfaces with the right governance controls.
Key implementation elements:
- API-first architecture for consistent access patterns
- Role-based access controls (data governance)
- Self-service capabilities data access
- Multiple consumption patterns supporting both batch and real-time use cases
Impact:
A financial services company implemented self-service data access and saw a 70% reduction in IT tickets related to data requests. More importantly, their fraud detection models could access real-time transaction data, improving detection rates by 40%.

Interoperable
Systems that work together
The problem:
Enterprise data often sits in disconnected systems with incompatible schemas and semantics, making AI models brittle when applied across domains. AI models trained on data from one system often fail when applied to data from another.
The FAIR solution:
Interoperable data uses common standards, formats, and semantic models that enable seamless integration across systems.
Key implementation elements:
- Standardized data formats and exchange protocols
- Common semantic models that define business concepts consistently
- Integration patterns that automate format translation
- Version management for compatibility over time
Impact:
A manufacturing company unified data from 15 regional systems using shared schemas and semantic models deploying predictive maintenance AI, originally built for one facility, across all locations without modification.
Reusable
Data products that scale
The problem:
Organizations often treat data as a byproduct, forcing each AI project to repeat preparation work.
The FAIR solution:
Reusable data is designed as products with clear interfaces, documentation, and quality, ready for multiple use cases.
Key implementation elements:
- Data product mindset that treats datasets as managed assets
- Clear documentation including quality metrics and usage guidelines
- Versioning and change management for backward compatibility
- Usage analytics to track how and by whom data products are consumed
Impact:
A telecommunications company created reusable data products for customer behaviour analysis. What started as a single churn prediction model became the foundation for 12 different AI applications, reducing development time by 60% for each new use case.
FAIR in action: A Healthcare example

Challenge:
A healthcare organization wanted to implement AI for patient risk assessment but struggled with data scattered across electronic health records, imaging systems, lab results, and insurance databases.
FAIR Implementation:
Findable: Implemented a healthcare data catalogue that could search across clinical notes, lab values, imaging metadata, and insurance claims using medical terminology.
Accessible: Created FHIR-compliant APIs that provided secure, standardized access to patient data with automatic anonymization for research use cases.
Interoperable: Adopted HL7 standards and common medical vocabularies (SNOMED, ICD-10) to ensure data could be combined meaningfully across source systems.
Reusable: Built data products around common clinical concepts (patient risk scores, medication histories, diagnostic timelines) that could support multiple AI applications.
Results:
- First AI model (sepsis prediction) deployed in 4 months instead of projected 18 months
- Same data foundation supported 6 additional AI use cases within first year
- 95% reduction in data preparation time for new clinical AI projects
- Full audit trail for regulatory compliance built into the architecture
Getting Started with FAIR:
A Practical Roadmap
To make FAIR principles stick, you need more than technology. You need alignment at the top.
Phase 0 is about creating the foundation: aligning leadership, establishing governance roles, and setting clear success metrics. This buy-in ensures the FAIR program becomes a business priority rather than just a technical exercise.

What success looks like
- Priority datasets FAIR scored
- Reusable data products feeding reproducible models in production
- Audit ready evidence for governance & compliance
- Measurable lift in time to data, model stability, and incident reduction
The ROI of FAIR data
Organizations that implement FAIR data principles typically see:
Immediate Benefits (6+ months):
- 50-70% reduction in data discovery time
- 40-60% faster AI project startup
- Improved data quality through standardized processes
Long-term Value (12+ months):
- 3-5x improvement in AI development velocity
- Significant reduction in technical debt and maintenance costs
- Enhanced regulatory compliance and risk management
- Foundation for data monetization and new business models
Conclusion: FAIR as your AI foundation
FAIR data principles aren't just good practice; they are essential for any organization serious about scaling AI responsibly. By making data Findable, Accessible, Interoperable, and Reusable, you create the foundation for AI success that compounds over time.
The question isn't whether you can afford to implement FAIR principles. It's whether you can afford not to.
Ready to make your data FAIR?
Datavid specializes in building FAIR-compliant data architectures that enable responsible AI at scale.