

3 minute read
According to Gartner, your business is set to incur, on average, ~$15M per year in costs due to poor quality data. IDC Market Research also states that companies can lose up to 30% in revenue annually due to inefficiencies resulting from incorrect or siloed data.

With roughly 2.5 quintillion bytes of data being generated every day, more data is now generated in one day than in the previous century.
This makes it impossible to dismiss data organization and communication as essential components of progress in any enterprise industry.
However, the cost of frequent data generation is often accompanied by data silos (data stored in isolated sources) and, in turn, the need to eliminate them.
What are data silos?
A data silo is a collection of isolated data. This data is restricted, unanalysed, and only available to a single department or unit within an organisation.
The information that has been stored or processed in a way makes it inaccessible to other departments, or unreadable to data processing tools.
What causes data silos?
Data silos occur for a variety of reasons, including organisational growth.
As organisations grow in revenue and staff, there is a desire to further divide parts of the organisation into smaller units for better management and monitoring.
This level of division has its drawbacks, as the data generated is stored internally, making knowledge-sharing difficult.
The use of multiple Saas-based data management applications or platforms is another understandable (but little considered) cause of data silos.
Not to mention the cost implications of these platforms.
There is almost no interaction between them, leading to solutions like Zapier or Microsoft Power Automate which increase the complexity of data management.
While it is recommended that enterprise organisations work with secondary sources to help organise their data, below are 3 factors to consider.
The cost of data silos
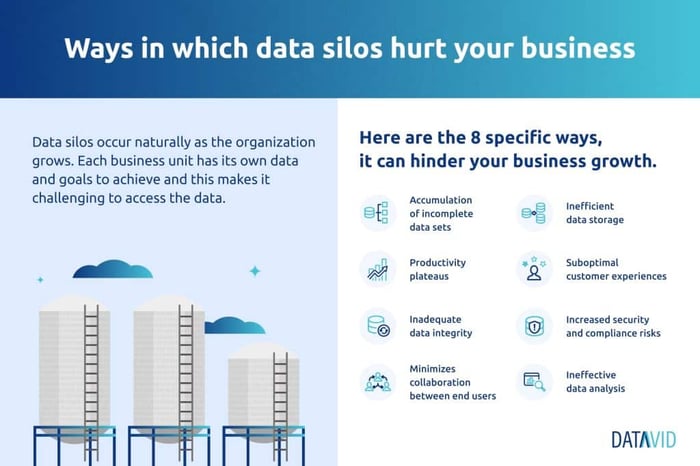
The general overview of all data silos problems is waste; data silos waste a lot of resources, finance, time, and personnel strength.
Data silos are inefficient
For enterprises, it’s difficult to identify the cost of data silos.
A careful examination of a large organisation’s activities - particularly the number of resources allocated to data storage, retrieval, and processing - will often reveal inefficiency and waste both in computing power and the workflow.
Data silos are costly
Due to redundant data infrastructures, the storage cost can increase significantly as many documents are duplicated across multiple sources, occupying more space.
Data silos waste time
When you need to make decisions, data silos result in slow progress.
The organisation is often unable to implement decisions that rely on collaborative data analysis to reach conclusive results because of the separation.
Redundant data also introduces the need to maintain multiple copies of the same records, resulting in inconsistency and wasted time.
Data silos reduce interaction
The presence of data silos makes information hard to reach. This reduces the opportunity for employees to make suggestions that will help the company grow.
It also stifles progress and innovation, reducing employees’ trust in the data provided and making collaboration more stressful among team members.
The solution to data silos
Data silos do not fade away easily. Your organisation needs to make a deliberate decision to overhaul infrastructure and policies from the top.
Employee rivalry that promotes information hoarding should be discouraged, and openness to sharing knowledge should be encouraged.
Employee rewards should be aligned with the company’s goal of acquiring and sharing knowledge across departments instead of fostering employee rivalry.
Though managerial decisions are vital in tackling data silos, solving them goes beyond that.
Organisations can tackle data silos manually by fostering a data-sharing and interaction culture, but this will be unreliable as your data stores grow in size.
The recommended approach is to deploy a knowledge engine - an intelligent decision-support tool that combines unstructured data with models and rules that fit your organisation - to carry out data-driven decisions or identify patterns.
Consider 3 benefits of knowledge engines:
Benefit #1: Interaction and collaboration
The value of big data comes from interpretation and predictive analysis.
Data ingestion tools like Datavid Rover eliminate the overhead cost of maintaining or developing third-party integration tools.
No more “handshakes.”
These tools guarantee centralised storage and reference while helping team members interact with data either in original or modified formats.
Benefit #2: Timely intervention
Enterprise data is collected at such a rate that no manual system can sort and process it accurately. There is a need for accuracy that meets the volume of data generated.
Enterprise organisations need to consider newer approaches to data sorting that do not compromise quality (such as Extract, Load, Transform).
Being able to load the data before it is transformed allows you to intervene quickly in case a variable or document type is missing, and so on.
Benefit #3: Simplified planning
Data silos do not appear overnight; they develop gradually, giving your organisation enough time before they become hard to manage.
By centralising your sources in one data hub, planning your entire data strategy becomes much simpler, and you can extract just the information you need.
Integrate your enterprise data at scale
Businesses struggle to harness the benefits of stores of data siloed away in different departments.
Pitfalls range from incomplete business info, waste of storage space, low integrity of data, suboptimal customer experience, and a slow pace of business growth.
Knowledge engines like Datavid Rover enable full integration, resulting in higher cost efficiency, improved productivity, and faster business growth.



