
3 minute read
Data discovery—along with data classification—provides a granular, 360-degree view of your business. Thanks to these practices, you can get a holistic picture of all the knowledge your business has to offer.

Enterprises can immensely benefit from data discovery and data classification as a part of a data protection strategy.
Data IS a critical asset, and it’s arguably the foundation of every business.
The cost of a data breach is huge; it has averaged $ 4.24 million in 2021 (IBM).
In the fight to avoid data loss, businesses face one major problem that hinders effective data protection- visibility.
Finding and identifying data is a complex process, even though it is essential for creating a robust data protection strategy.
For these reasons, having effective data discovery and classification will help.
What is data discovery and classification?
Data discovery and classification differ in process, but they have to work hand in hand to offer complete data visibility for maximized analysis and security.
Before getting into how they two work together, let’s first define each term.
Data discovery
Data discovery involves scanning an organization’s entire environment to identify where their structured and unstructured data resides.
A comprehensive data discovery process will check on the company servers and hardware to determine the location of sensitive and regulated data.
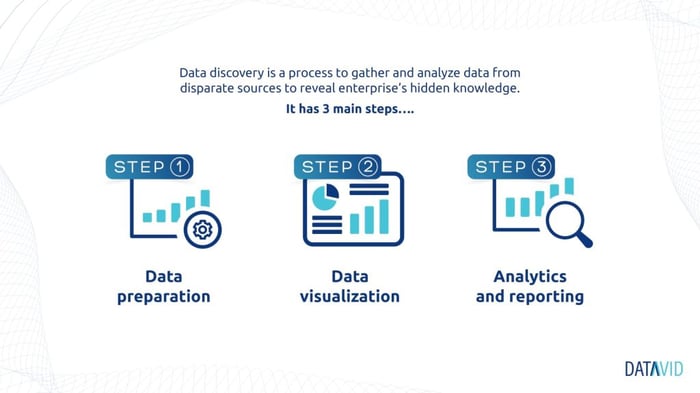
Data discovery has three major steps:
- Data preparation: This is the preprocessing step which involves statistical techniques to combine the company’s unstructured, raw data from numerous sources. Data is then transformed by eliminating noise into a usable format of high quality offering a consistent view.
- Data visualization: This process is critical for analyzing big data. It provides essential insights and accurate information for predictive analytics enabling the enterprise to make informed decisions.
- Advanced analytics and reporting: In this step, companies summarize, organize, and break down data into intelligible reports that are seamless to understand and usable for making data-driven decisions.
The process is essential for identifying, classifying, and tracking sensitive data.
The outcome is complete visibility of where data resides.
It becomes easy to protect data as well as remain compliant with regulations.
Data classification
Data classification is the process of organizing the data discovered into specific categories based on its file type, content, and other related metadata.
It facilitates easily locating sensitive data and eliminates multiple duplications percentage storage waste and data breaches.
Data classification has 3 main types according to industry standards:
- Content-based classification: Involves classifying data based on the information they hold e.g. sensitive, personal, and confidential information.
- Context-based classification: Here, the data is classified according to metadata instead of their content. This includes the location where data was created or modified, the data’s application, and the data’s creator.
- User-based classification: This classification depends mainly on each file’s manual, and end-user selection. It relies on user discretion to classify data and flag any sensitive data.
The result is reduced storage, backup costs, data visibility, and increased compliance regulations.
How data discovery and classification work
Data discovery and classification go hand in hand to give complete visibility on business data, including where it resides and the policies needed to protect sensitive data from breaches.
Adequate data discovery and classification result in a more controlled environment where you can deal with intruders and keep data safe.
The importance of discovery and classification to organizations
Combining data discovery and data classification helps organizations realize several data security benefits. Some of the top benefits you can achieve are:
Benefit #1: Gain complete visibility into your data
The complete view of data provides greater control and accessibility of the sensitive data. It becomes easy to bridge security gaps that are otherwise hidden.
This ensures robust and improved data security.
Benefit #2: Achieve regulatory compliance
Data discovery ensures the data lives in complaint locations and is moved around the organization in a controlled and appropriate way.
On the other hand, data classifications help group data as regulations require.
This enables the creation of the right policies for storing and moving data easily.
Benefit #3: Focus on your most vulnerable areas
After data discovering your company data, you can classify them to empower your business to focus on essential areas of your business.
For instance, you will have visibility on your cybersecurity resources, which protect specific data groupings. You can then optimize them for improved security.

The challenges of data discovery and classification
Although companies can benefit significantly from implementing data discovery and classification, most businesses still struggle to start.
The reason for this is its complexity.
Businesses have a massive amount of structured and unstructured data scattered in the cloud, on-premise locations, and across pieces of hardware.
With these unorganized silos of data, tracking and classifying are challenging.
To make this even more complicated, business data is dynamic. It constantly changes with movement, and the regulation governing these data also keeps changing.
Take your first step towards new data insights
Businesses must adopt new technologies and systems to keep up with these changes. As a result of the complexities, most businesses lack the time, resources, and even expertise to do this manually. That’s where data discovery and classification platforms like Datavid Rover come in.

With a solution like Datavid Rover, you can gain control of your data, dramatically improve data security, and achieve compliance standards with data intelligence.
Data discovery and classification open doors to new insights, transforming your raw data selection into usable data intelligence. You can use this to fuel value-creating and risk management in your modern enterprise.

Frequently Asked Questions


